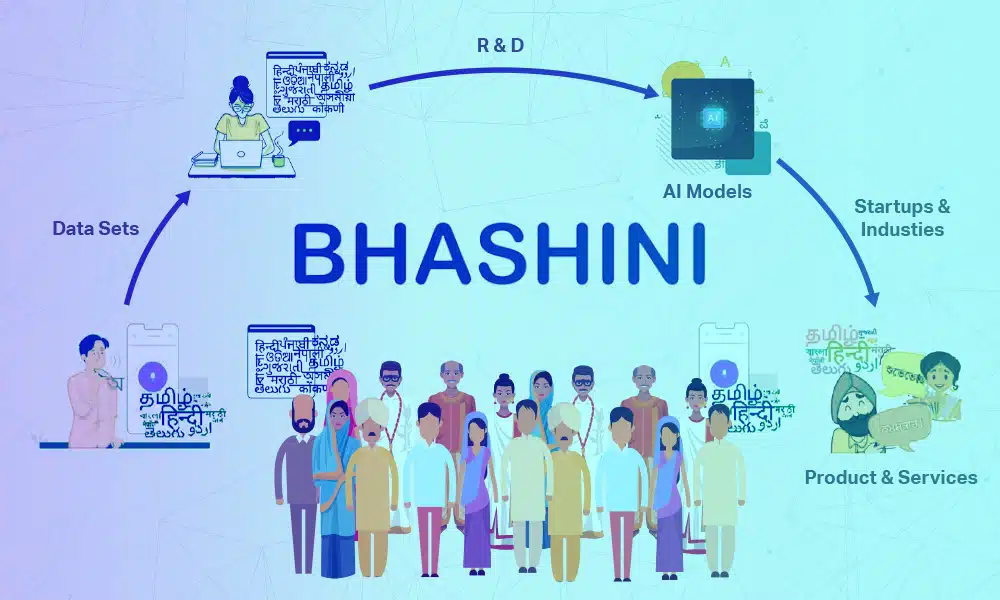
Todos nós interagimos com aplicativos de IA de conversação, como Alexa, Siri e Google Home. Esses aplicativos tornaram nosso dia-a-dia muito mais fácil e melhor.
A IA de conversação está impulsionando o futuro da tecnologia moderna e facilitando a comunicação aprimorada entre humanos e máquinas. Ao projetar um assistente de bate-papo contínuo que funcione de maneira eficaz e precisa, você também deve estar ciente dos muitos desafios de desenvolvimento que pode encontrar.
Aqui, vamos falar sobre:
- Vários desafios de dados comuns
- Como isso afeta os consumidores?
- As melhores maneiras de superar esses desafios e muito mais.
Desafios comuns de dados na IA conversacional
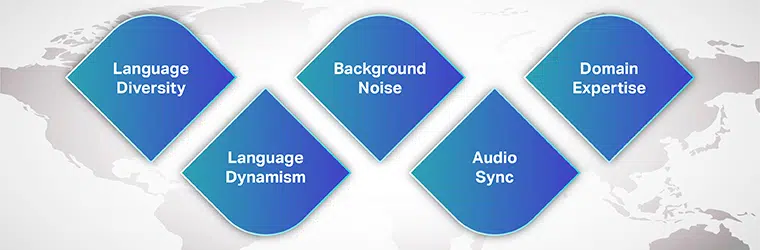
Com base em nossa experiência trabalhando com os principais clientes e projetos complexos, compilamos uma lista dos desafios de dados de IA conversacionais mais comuns para você.
Diversidade de Idiomas
Construir um assistente de bate-papo baseado em IA que possa atender à diversidade de idiomas é um grande desafio.
Há cerca de 1.35 bilhão de pessoas que falam inglês como segunda língua ou como língua nativa. Isso significa que menos de 20% da população mundial fala inglês, deixando o restante da população conversando em outros idiomas além do inglês. Portanto, se você estiver criando um assistente de bate-papo conversacional, também deve considerar a diversidade de fatores linguísticos.
Dinamismo da linguagem
Qualquer linguagem é dinâmica, e capturar seu dinamismo e treinar um algoritmo de aprendizado de máquina baseado em IA não é fácil. Dialetos, pronúncia, gírias e nuances pode afetar a proficiência de um modelo de IA.
No entanto, o maior desafio para um aplicativo baseado em IA é decifrar com precisão o fator humano na entrada do idioma. Os seres humanos trazem sentimentos e emoções na briga, tornando difícil para a ferramenta de IA compreender e reagir.
Barulho de fundo
O ruído de fundo pode estar em conversas simultâneas ou outros sons sobrepostos.
Limpando sua coleção de áudio de interferência de ruídos de fundo, como campainhas, cães latindo ou crianças falar em segundo plano é crucial para o sucesso do aplicativo.
Além disso, hoje em dia, os aplicativos de IA precisam lidar com assistentes de voz concorrentes presentes nas mesmas instalações. Torna-se difícil para o assistente de voz distinguir entre comandos de voz humanos e outros assistentes de voz quando isso acontece.
Sincronização de áudio
Ao extrair dados de uma conversa telefônica para treinar o assistente virtual, é possível ter o chamador e o agente em duas linhas diferentes. É vital ter áudios de ambos os lados para serem sincronizados e conversas capturadas sem fazer referência cruzada a cada arquivo.
Falta de dados específicos do domínio
Um aplicativo baseado em IA também deve processar linguagem específica do domínio. Embora os assistentes de voz estejam mostrando uma promessa excepcional em processamento de linguagem natural, ainda está para provar seu domínio sobre a linguagem específica do setor. Por exemplo, geralmente não fornece respostas a perguntas específicas de domínio sobre indústrias automobilísticas ou financeiras.
Como esses desafios afetam os consumidores?
Os assistentes de bate-papo de IA conversacional podem ser semelhantes à pesquisa baseada em texto. Mas, existe uma diferença básica entre os dois. No suporte à pesquisa baseada em texto, o aplicativo oferece uma lista de resultados de pesquisa relevantes que o usuário pode escolher, dando aos usuários a flexibilidade necessária na escolha de uma das opções.
No entanto, em uma IA conversacional, os usuários geralmente não obtêm mais de uma opção e também esperam que o aplicativo forneça o melhor resultado.
Se a ferramenta de inteligência artificial vier com viés de dados, certamente o resultado não será preciso ou confiável. Os resultados podem ser influenciados pela popularidade e não pelos requisitos do usuário, tornando o resultado redundante.
A solução: superando os desafios durante a fase de coleta de dados
O primeiro passo para combater o viés de treinamento seria a conscientização e a aceitação. Depois de saber que seu conjunto de dados pode estar repleto de vieses, você deve tomar medidas corretivas.
A próxima etapa seria fornecer controles proativamente ao usuário para alterar as configurações para compensar o viés diretamente. Ou, o feedback pode ser inserido no sistema para mitigar os problemas de viés de forma proativa.
A mitigação do ruído de fundo, conversas simultâneas e manuseio de várias pessoas exigem técnicas aprimoradas de identificação de voz. O sistema também deve ser treinado para entender a conversa contextual e as palavras ou frases.
A capacidade de identificar vozes não humanas também pode ser aprimorada quando o sistema é introduzido para abordar pessoas ou vozes não registradas.
Quando se trata de diversidade de idiomas, a solução está em aumentar o número de conjuntos de dados de idiomas usados para treinar o modelo. Assim, quando as empresas aumentam o número de sistemas para atender a grandes mercados linguísticos, a diversidade linguística pode ser alcançada sem problemas.
Benefícios de trabalhar com fornecedores externos
Há vários benefícios em trabalhar com fornecedores externos, pois eles ajudam a mitigar alguns dos desafios de coleta de dados de conversação.
Trabalhar com fornecedores terceirizados experientes oferece maior eficiência de custo e confiabilidade. É rentável para obtenha conjuntos de dados de qualidade de fornecedores confiáveis em vez de adquirir a coleta de dados de conjuntos de dados de treinamento de IA conversacional de código aberto.
Embora os vieses estejam presentes em todos os conjuntos de dados, com um fornecedor externo, você pode reduzir o custo associado ao retrabalho ou retreinamento de seu modelo devido a discrepâncias de dados e vieses excessivos de idioma.
Um fornecedor experiente também ajudará você a economizar tempo em coleta de dados e anotação precisa. Um fornecedor externo terá o conhecimento linguístico necessário para desenvolver modelos de IA que possam abrir novos mercados para sua empresa.
Um fornecedor pode fornecer conjuntos de dados personalizáveis de alta qualidade que atendem às suas preferências e requisitos de modelo. Nem todas as soluções de anotação e coleta de dados pré-empacotadas podem funcionar a seu favor quando se trata de atendimento ao cliente aprimorado, taxas de conversão mais altas e custos de negócios reduzidos.
Temos os dados de conversação que seu modelo de IA precisa.
Como fornecedor confiável e experiente, Shaip tem uma coleção enorme de conjuntos de dados de IA conversacionais para todos os tipos de modelos de aprendizado de máquina. Além disso, também fornecemos dados de conversação totalmente personalizados em vários idiomas, dialetos e vernáculos. Se você deseja desenvolver um aplicativo de suporte por chat baseado em IA confiável e preciso, temos todas as ferramentas que podem tornar seu projeto um sucesso.