



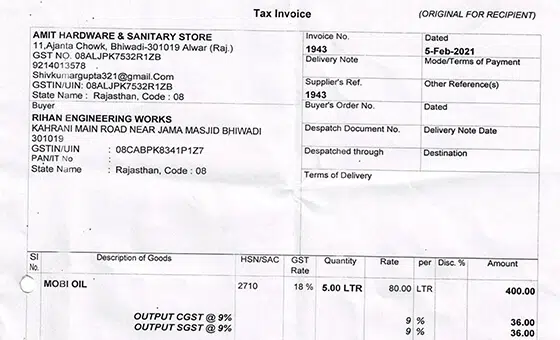

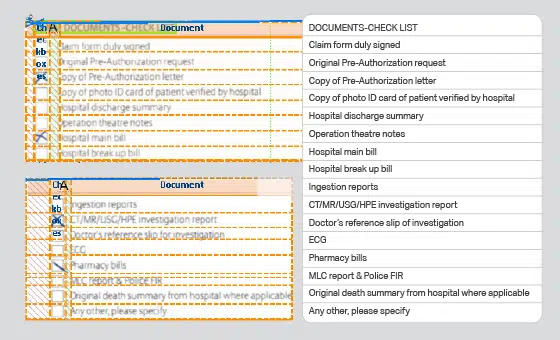


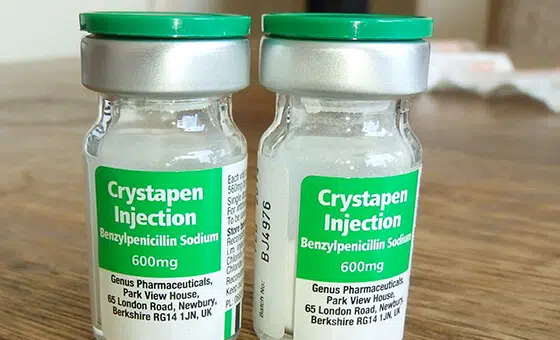



- Caso de uso: Modelo de Reconhecimento de Objetos
- Formato: Vídeos
- Volume: 5,000+
- Anotação: Não

- Caso de uso: Doc. Modelo de reconhecimento
- Formato: Imagens
- Volume: 15,900+
- Anotação: Não
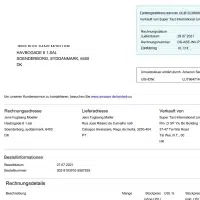
- Caso de uso: Reconhecimento de fatura. Modelo
- Formato: Imagens
- Volume: 45,000+
- Anotação: Não

- Caso de uso: Nº Reconhecimento de Placa
- Formato: Imagens
- Volume: 3,500+
- Anotação: Não

- Caso de uso: Modelo OCR
- Formato: Imagens
- Volume: 90,000+
- Anotação: Sim

- Caso de uso: Modelo OCR multilíngue
- Formato: Imagens
- Volume: 23,500+
- Anotação: Sim
- Caso de uso: Modelo de detecção de objetos
- Formato: Imagens
- Volume: 11,500+
- Anotação: Não

- Caso de uso: Modelos de IA de recibo
- Formato: Imagens
- Volume: 75,000+
- Anotação: Não

Pessoas
Equipes dedicadas e treinadas:
- Mais de 30,000 colaboradores para coleta de dados, rotulagem e controle de qualidade
- Equipe de gerenciamento de projetos credenciada
- Equipe de desenvolvimento de produto experiente
- Equipe de integração e terceirização de pool de talentos

Extração
A mais alta eficiência do processo é garantida com:
- Processo robusto 6 Sigma Stage-Gate
- Uma equipe dedicada de black belts 6 Sigma - Principais proprietários de processos e conformidade de qualidade
- Melhoria Contínua e Feedback Loop

Plataforma
A plataforma patenteada oferece benefícios:
- Plataforma ponta a ponta baseada na web
- Qualidade impecável
- TAT mais rápido
- Entrega perfeita



A criação de PNL clínica é uma tarefa crítica que requer uma grande experiência de domínio para ser resolvida. Posso ver claramente que você está vários anos à frente do Google nessa área. Eu quero trabalhar com você e escalar você.
Google Inc. Diretor
Minha equipe de engenharia trabalhou com a equipe de Shaip por mais de 2 anos durante o desenvolvimento de APIs de fala para saúde. Ficamos impressionados com o trabalho realizado em PNL específica para saúde e com o que eles são capazes de alcançar com conjuntos de dados complexos.
Google Inc. Chefe de Engenharia