
Estima-se que, em média, o adulto toma decisões sobre a vida e as coisas cotidianas com base no aprendizado passado. Estas, por sua vez, vêm de experiências de vida moldadas por situações e pessoas. No sentido literal, situações, instâncias e pessoas nada mais são do que dados que são alimentados em nossas mentes. À medida que acumulamos anos de dados na forma de experiência, a mente humana tende a tomar decisões ininterruptas.
O que isso transmite? Esses dados são inevitáveis no aprendizado.
Assim como uma criança precisa de um rótulo chamado alfabeto para entender as letras A, B, C, D, uma máquina também precisa entender os dados que está recebendo.
Isso é exatamente o que Artificial Intelligence (AI) treinamento é tudo. Uma máquina não é diferente de uma criança que ainda precisa aprender coisas com o que está prestes a ser ensinado. A máquina não sabe diferenciar entre um gato e um cachorro ou um ônibus e um carro porque eles ainda não experimentaram esses itens ou aprenderam como eles se parecem.
Assim, para alguém que constrói um carro autônomo, a principal função que precisa ser adicionada é a capacidade do sistema de entender todos os elementos cotidianos que o carro pode encontrar, para que o veículo possa identificá-los e tomar as decisões de direção apropriadas. Este é o lugar onde Dados de treinamento de IA entra em jogo.
Hoje, os módulos de inteligência artificial nos oferecem muitas conveniências na forma de mecanismos de recomendação, navegação, automação e muito mais. Tudo isso acontece devido ao treinamento de dados de IA que foi usado para treinar os algoritmos enquanto eles eram construídos.
Os dados de treinamento de IA são um processo fundamental na construção aprendizado de máquina e algoritmos de IA. Se você estiver desenvolvendo um aplicativo baseado nesses conceitos de tecnologia, precisará treinar seus sistemas para entender os elementos de dados para processamento otimizado. Sem treinamento, seu modelo de IA será ineficiente, falho e potencialmente inútil.
O que são dados de treinamento de IA?
Os dados de treinamento de IA são informações cuidadosamente selecionadas e limpas que são inseridas em um sistema para fins de treinamento. Esse processo faz ou quebra o sucesso de um modelo de IA. Pode ajudar a desenvolver a compreensão de que nem todos os animais de quatro patas em uma imagem são cães ou pode ajudar um modelo a diferenciar entre gritos de raiva e risadas alegres. É o primeiro estágio na construção de módulos de inteligência artificial que exigem dados de alimentação de colher para ensinar às máquinas o básico e permitir que elas aprendam à medida que mais dados são alimentados. Isso, novamente, abre caminho para um módulo eficiente que produz resultados precisos para os usuários finais.

Considere um processo de dados de treinamento de IA como uma sessão de prática para um músico, onde quanto mais eles praticam, melhor eles ficam em uma música ou escala. A única diferença aqui é que as máquinas também precisam primeiro aprender o que é um instrumento musical. Semelhante ao músico que faz bom uso das inúmeras horas gastas em prática no palco, um modelo de IA oferece uma ótima experiência aos consumidores quando implantado.

Que tipos de dados eu preciso?
Existem 4 tipos principais de dados que seriam necessários, ou seja, Imagem, Vídeo, Áudio/Fala ou Texto para treinar efetivamente os modelos de aprendizado de máquina. O tipo de dados necessários dependeria de uma variedade de fatores, como o caso de uso em questão, a complexidade dos modelos a serem treinados, o método de treinamento usado e a diversidade de dados de entrada necessários.
Quantos dados são adequados?
Eles dizem que não há fim para o aprendizado e essa frase é ideal no espectro de dados de treinamento de IA. Quanto mais dados, melhores os resultados. No entanto, uma resposta tão vaga quanto essa não é suficiente para convencer quem deseja lançar um aplicativo com inteligência artificial. Mas a realidade é que não existe uma regra geral, uma fórmula, um índice ou uma medida do volume exato de dados necessários para treinar seus conjuntos de dados de IA.

Um especialista em aprendizado de máquina revelaria comicamente que um algoritmo ou módulo separado deve ser construído para deduzir o volume de dados necessários para um projeto. Essa é, infelizmente, a realidade também.
Agora, há uma razão pela qual é extremamente difícil limitar o volume de dados necessários para o treinamento de IA. Isso se deve às complexidades envolvidas no próprio processo de treinamento. Um módulo de IA compreende várias camadas de fragmentos interconectados e sobrepostos que influenciam e complementam os processos uns dos outros.
Por exemplo, vamos considerar que você está desenvolvendo um aplicativo simples para reconhecer um coqueiro. Do ponto de vista, parece bastante simples, certo? Do ponto de vista da IA, no entanto, é muito mais complexo.
No início, a máquina está vazia. Ele não sabe o que é uma árvore em primeiro lugar, muito menos uma árvore frutífera tropical alta, específica da região. Para isso, a modelo precisa ser treinada sobre o que é uma árvore, como diferenciar de outros objetos altos e esbeltos que podem aparecer em molduras como postes de luz ou postes de eletricidade e depois passar a ensiná-la as nuances de um coqueiro. Uma vez que o módulo de aprendizado de máquina tenha aprendido o que é um coqueiro, pode-se presumir com segurança que ele sabe como reconhecê-lo.
Mas somente quando você alimenta uma imagem de uma figueira, você perceberia que o sistema identificou erroneamente uma figueira para um coqueiro. Para um sistema, qualquer coisa que seja alta com folhagem agrupada é um coqueiro. Para eliminar isso, o sistema precisa agora entender cada árvore que não é um coqueiro para identificar com precisão. Se este é o processo para um aplicativo unidirecional simples com apenas um resultado, podemos imaginar as complexidades envolvidas em aplicativos desenvolvidos para saúde, finanças e muito mais.

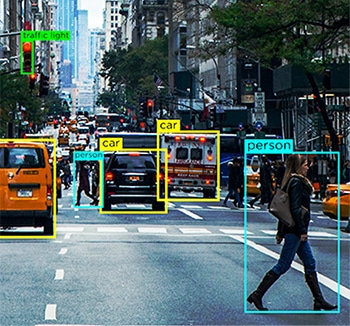


Como melhorar a qualidade dos dados?
A qualidade dos dados é diretamente proporcional à qualidade da saída. É por isso que modelos altamente precisos exigem conjuntos de dados de alta qualidade para treinamento. No entanto, há um porém. Para um conceito que depende de precisão e exatidão, o conceito de qualidade é muitas vezes bastante vago.
Dados de alta qualidade parecem fortes e confiáveis, mas o que isso realmente significa?
O que é qualidade em primeiro lugar?
Bem, como os próprios dados que alimentamos em nossos sistemas, a qualidade também tem muitos fatores e parâmetros associados. Se você entrar em contato com especialistas em IA ou veteranos de aprendizado de máquina, eles podem compartilhar qualquer permutação de dados de alta qualidade – qualquer coisa que seja –

- Uniforme – dados provenientes de uma fonte específica ou uniformidade em conjuntos de dados provenientes de várias fontes
- Cuidado integral – dados que cobrem todos os cenários possíveis em que seu sistema se destina a trabalhar
- Consistente – cada byte de dados é de natureza semelhante
- Relevante – os dados que você obtém e alimenta são semelhantes aos seus requisitos e resultados esperados e
- variado - você tem uma combinação de todos os tipos de dados, como áudio, vídeo, imagem, texto e muito mais
Agora que entendemos o que significa qualidade em qualidade de dados, vamos analisar rapidamente as diferentes maneiras de garantir a qualidade coleta de dados e geração.
O que afeta a qualidade dos dados de treinamento?
Existem três fatores principais que podem ajudá-lo a prever o nível de qualidade que você deseja para seus modelos de IA/ML. Os 3 fatores-chave são Pessoas, Processos e Plataformas que podem fazer ou quebrar seu projeto de IA.
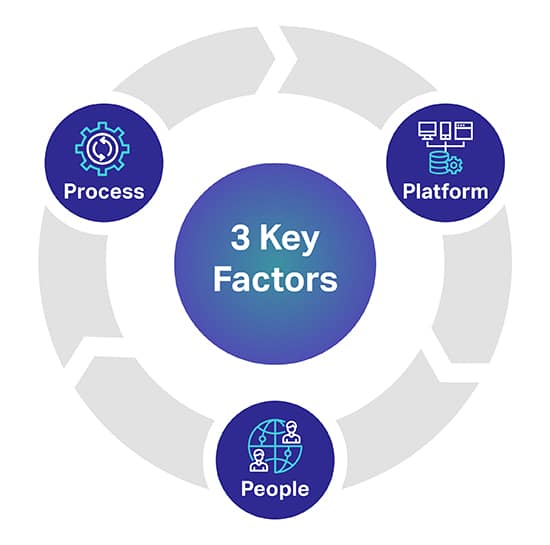
Plataforma: É necessária uma plataforma proprietária humana completa para obter, transcrever e anotar diversos conjuntos de dados para implantar com sucesso as iniciativas de IA e ML mais exigentes. A plataforma também é responsável por gerenciar os trabalhadores e maximizar a qualidade e o rendimento
Pessoas: Para fazer a IA pensar de forma mais inteligente, são necessárias pessoas que são algumas das mentes mais inteligentes do setor. Para escalar, você precisa de milhares desses profissionais em todo o mundo para transcrever, rotular e anotar todos os tipos de dados.
Processo: Fornecer dados padrão-ouro consistentes, completos e precisos é um trabalho complexo. Mas é o que você sempre precisará entregar, de modo a aderir aos mais altos padrões de qualidade, bem como a controles de qualidade e pontos de verificação rigorosos e comprovados.
De onde você obtém dados de treinamento de IA?
Ao contrário de nossa seção anterior, temos uma visão muito precisa aqui. Para aqueles que procuram obter dados
ou se você estiver no processo de coleta de vídeo, coleta de imagens, coleta de texto e mais, há três
principais vias de onde você pode obter seus dados.
Vamos explorá-los individualmente.
Fontes gratuitas
Fontes livres são avenidas que são repositórios involuntários de grandes volumes de dados. São dados que estão simplesmente ali na superfície de graça. Alguns dos recursos gratuitos incluem –

- Conjuntos de dados do Google, onde mais de 250 milhões de conjuntos de dados foram lançados em 2020
- Fóruns como Reddit, Quora e outros, que são fontes engenhosas de dados. Além disso, as comunidades de ciência de dados e IA nesses fóruns também podem ajudá-lo com conjuntos de dados específicos quando contatados.
- Kaggle é outra fonte gratuita onde você pode encontrar recursos de aprendizado de máquina além de conjuntos de dados gratuitos.
- Também listamos conjuntos de dados abertos gratuitos para você começar a treinar seus modelos de IA
Embora essas avenidas sejam gratuitas, o que você acabaria gastando é tempo e esforço. Os dados de fontes gratuitas estão por toda parte e você precisa dedicar horas de trabalho para sourcing, limpeza e adaptação para atender às suas necessidades.
Um dos outros pontos importantes a serem lembrados é que alguns dos dados de fontes gratuitas também não podem ser usados para fins comerciais. Isso requer licenciamento de dados.
Conjuntos de Dados Abertos – Usar ou não usar?
 Conjuntos de dados abertos são conjuntos de dados disponíveis publicamente que podem ser usados para projetos de aprendizado de máquina. Não importa se você precisa de um conjunto de dados baseado em áudio, vídeo, imagem ou texto, existem conjuntos de dados abertos disponíveis para todas as formas e classes de dados.
Conjuntos de dados abertos são conjuntos de dados disponíveis publicamente que podem ser usados para projetos de aprendizado de máquina. Não importa se você precisa de um conjunto de dados baseado em áudio, vídeo, imagem ou texto, existem conjuntos de dados abertos disponíveis para todas as formas e classes de dados.
Por exemplo, há o conjunto de dados de avaliações de produtos da Amazon que apresenta mais de 142 milhões de avaliações de usuários de 1996 a 2014. Para imagens, você tem um excelente recurso como o Google Open Images, onde pode obter conjuntos de dados de mais de 9 milhões de fotos. O Google também tem uma ala chamada Machine Perception que oferece cerca de 2 milhões de clipes de áudio com dez segundos de duração.
Apesar da disponibilidade desses recursos (e outros), o fator importante que muitas vezes é negligenciado são as condições que acompanham seu uso. Eles são públicos com certeza, mas há uma linha tênue entre violação e uso justo. Cada recurso vem com sua própria condição e se você estiver explorando essas opções, sugerimos cautela. Isso porque, a pretexto de preferir avenidas livres, você pode acabar incorrendo em ações judiciais e despesas afins.
Os verdadeiros custos dos dados de treinamento de IA
Apenas o dinheiro que você gasta para adquirir os dados ou gerar dados internamente não é o que você deve considerar. Devemos considerar elementos lineares como tempo e esforços gastos no desenvolvimento de sistemas de IA e custo do ponto de vista transacional. deixa de elogiar o outro.
Tempo gasto no fornecimento e anotação de dados
Fatores como geografia, demografia de mercado e concorrência em seu nicho dificultam a disponibilidade de conjuntos de dados relevantes. O tempo gasto na busca manual de dados é uma perda de tempo no treinamento do seu sistema de IA. Depois de conseguir obter seus dados, você atrasará ainda mais o treinamento gastando tempo anotando os dados para que sua máquina possa entender o que está sendo alimentado.
O Preço da Coleta e Anotação de Dados
As despesas gerais (coletores de dados internos, anotadores, equipamentos de manutenção, infraestrutura de tecnologia, assinaturas de ferramentas SaaS, desenvolvimento de aplicativos proprietários) devem ser calculadas durante o fornecimento de dados de IA
O custo de dados ruins
Dados ruins podem custar o moral da equipe da sua empresa, sua vantagem competitiva e outras consequências tangíveis que passam despercebidas. Definimos dados ruins como qualquer conjunto de dados impuro, bruto, irrelevante, desatualizado, impreciso ou cheio de erros de ortografia. Dados ruins podem estragar seu modelo de IA introduzindo viés e corrompendo seus algoritmos com resultados distorcidos.
Despesas de Gestão
Todos os custos que envolvem a administração da sua organização ou empresa, tangíveis e intangíveis constituem despesas de gestão que muitas vezes são as mais caras.

O que vem depois do Data Sourcing?
Depois de ter o conjunto de dados em mãos, o próximo passo é anotá-lo ou rotulá-lo. Depois de todas as tarefas complexas, o que você tem são dados brutos limpos. A máquina ainda não consegue entender os dados que você tem porque não estão anotados. É aqui que começa a parte restante do verdadeiro desafio.
Como mencionamos, uma máquina precisa de dados em um formato que ela possa entender. Isso é exatamente o que a anotação de dados faz. Ele pega dados brutos e adiciona camadas de rótulos e tags para ajudar um módulo a entender cada elemento dos dados com precisão.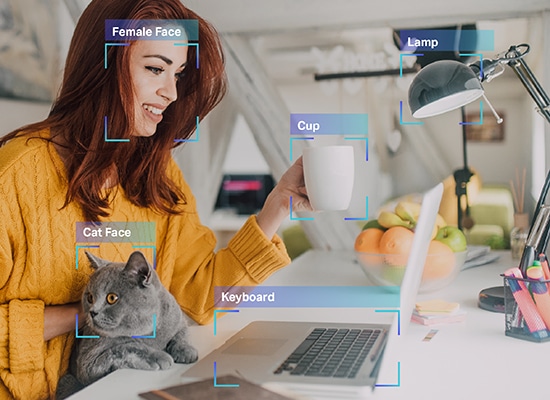
Por exemplo, em um texto, a rotulagem de dados informará a um sistema de IA a sintaxe gramatical, partes do discurso, preposições, pontuações, emoção, sentimento e outros parâmetros envolvidos na compreensão da máquina. É assim que os chatbots entendem melhor as conversas humanas e somente quando fazem isso podem imitar melhor as interações humanas por meio de suas respostas.
Por mais inevitável que pareça, também é extremamente demorado e tedioso. Independentemente da escala do seu negócio ou de suas ambições, o tempo necessário para anotar dados é enorme.
Isso ocorre principalmente porque sua força de trabalho existente precisa dedicar um tempo fora de sua agenda diária para anotar dados se você não tiver especialistas em anotação de dados. Portanto, você precisa convocar os membros da sua equipe e atribuir isso como uma tarefa adicional. Quanto mais demora, mais tempo leva para treinar seus modelos de IA.
Embora existam ferramentas gratuitas para anotação de dados, isso não tira o fato de que esse processo é demorado.
É aí que entram os fornecedores de anotação de dados como Shaip. Eles trazem uma equipe dedicada de especialistas em anotação de dados com eles para se concentrar apenas em seu projeto. Eles oferecem soluções da maneira que você deseja para suas necessidades e exigências. Além disso, você pode definir um cronograma com eles e exigir que o trabalho seja concluído nesse cronograma específico.
Um dos principais benefícios está no fato de que os membros de sua equipe interna podem continuar a se concentrar no que é mais importante para suas operações e projetos, enquanto os especialistas fazem o trabalho de anotar e rotular os dados para você.
Com a terceirização, a qualidade ideal, o tempo mínimo e a máxima precisão podem ser garantidos.