
Introdução
Este guia será extremamente útil para os compradores e tomadores de decisão que estão começando a se concentrar nos detalhes do fornecimento e implementação de dados para redes neurais e outros tipos de operações de IA e ML.

Este artigo é totalmente dedicado a esclarecer o que é o processo, por que é inevitável, crucial
fatores que as empresas devem considerar ao abordar ferramentas de anotação de dados e muito mais. Portanto, se você possui um negócio, prepare-se para se informar, pois este guia o guiará por tudo o que você precisa saber sobre anotação de dados.
Vamos começar.
Para aqueles que estão lendo o artigo, aqui estão algumas dicas rápidas que você encontrará no guia:
- Entenda o que é anotação de dados
- Conheça os diferentes tipos de processos de anotação de dados
- Conheça as vantagens de implementar o processo de anotação de dados
- Obtenha clareza sobre se você deve optar pela rotulagem de dados interna ou terceirizada
- Insights sobre como escolher a anotação de dados certa também
O que é a Aprendizagem de Máquinas?
 Já falamos sobre como a anotação de dados ou rotulagem de dados suporta aprendizado de máquina e que consiste em marcar ou identificar componentes. Mas quanto ao aprendizado profundo e ao aprendizado de máquina em si: a premissa básica do aprendizado de máquina é que sistemas e programas de computador podem melhorar seus resultados de maneiras que se assemelham a processos cognitivos humanos, sem ajuda ou intervenção humana direta, para nos fornecer insights. Em outras palavras, eles se tornam máquinas de autoaprendizagem que, assim como um ser humano, se tornam melhores em seu trabalho com mais prática. Essa “prática” é obtida analisando e interpretando mais (e melhores) dados de treinamento.
Já falamos sobre como a anotação de dados ou rotulagem de dados suporta aprendizado de máquina e que consiste em marcar ou identificar componentes. Mas quanto ao aprendizado profundo e ao aprendizado de máquina em si: a premissa básica do aprendizado de máquina é que sistemas e programas de computador podem melhorar seus resultados de maneiras que se assemelham a processos cognitivos humanos, sem ajuda ou intervenção humana direta, para nos fornecer insights. Em outras palavras, eles se tornam máquinas de autoaprendizagem que, assim como um ser humano, se tornam melhores em seu trabalho com mais prática. Essa “prática” é obtida analisando e interpretando mais (e melhores) dados de treinamento.
O que é anotação de dados?
A anotação de dados é o processo de atribuir, marcar ou rotular dados para ajudar os algoritmos de aprendizado de máquina a entender e classificar as informações que processam. Esse processo é essencial para treinar modelos de IA, permitindo que eles compreendam com precisão vários tipos de dados, como imagens, arquivos de áudio, imagens de vídeo ou texto.
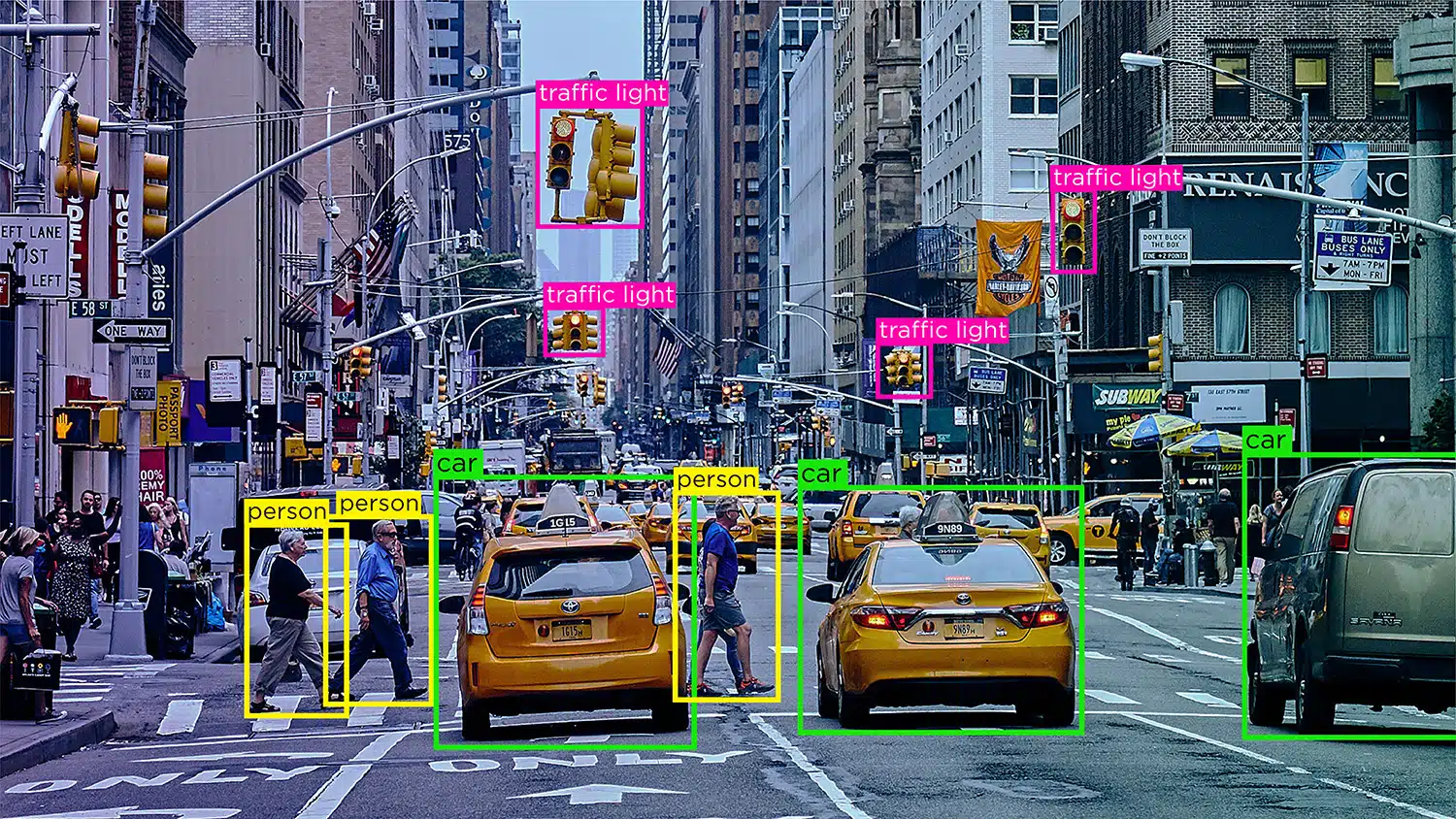
Imagine um carro autônomo que depende de dados de visão computacional, processamento de linguagem natural (NLP) e sensores para tomar decisões de direção precisas. Para ajudar o modelo de IA do carro a diferenciar entre obstáculos como outros veículos, pedestres, animais ou bloqueios de estradas, os dados recebidos devem ser rotulados ou anotados.
No aprendizado supervisionado, a anotação de dados é especialmente crucial, pois quanto mais dados rotulados são alimentados no modelo, mais rápido ele aprende a funcionar de forma autônoma. Os dados anotados permitem que os modelos de IA sejam implantados em vários aplicativos, como chatbots, reconhecimento de fala e automação, resultando em desempenho ideal e resultados confiáveis.
O que é uma ferramenta de rotulagem/anotação de dados?
 Em termos simples, é uma plataforma ou portal que permite que especialistas e especialistas anotem, marquem ou rotulem conjuntos de dados de todos os tipos. É uma ponte ou um meio entre os dados brutos e os resultados que seus módulos de aprendizado de máquina produziriam.
Em termos simples, é uma plataforma ou portal que permite que especialistas e especialistas anotem, marquem ou rotulem conjuntos de dados de todos os tipos. É uma ponte ou um meio entre os dados brutos e os resultados que seus módulos de aprendizado de máquina produziriam.
Uma ferramenta de rotulagem de dados é uma solução local ou baseada em nuvem que anota dados de treinamento de alta qualidade para modelos de aprendizado de máquina. Embora muitas empresas dependam de um fornecedor externo para fazer anotações complexas, algumas organizações ainda têm suas próprias ferramentas que são personalizadas ou baseadas em ferramentas freeware ou de código aberto disponíveis no mercado. Essas ferramentas geralmente são projetadas para lidar com tipos de dados específicos, ou seja, imagem, vídeo, texto, áudio, etc. As ferramentas oferecem recursos ou opções como caixas delimitadoras ou polígonos para anotadores de dados rotularem imagens. Eles podem simplesmente selecionar a opção e realizar suas tarefas específicas.
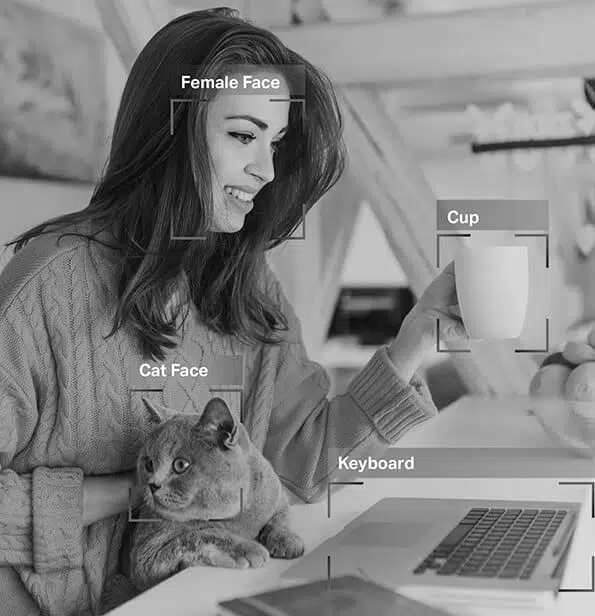
Anotação de imagem

A partir dos conjuntos de dados em que eles foram treinados, eles podem diferenciar instantaneamente e com precisão seus olhos de seu nariz e sua sobrancelha de seus cílios. É por isso que os filtros que você aplica se encaixam perfeitamente, independentemente do formato do seu rosto, da proximidade da câmera e muito mais.
Então, como você já sabe, anotação de imagem é vital em módulos que envolvem reconhecimento facial, visão computacional, visão robótica e muito mais. Quando os especialistas em IA treinam esses modelos, eles adicionam legendas, identificadores e palavras-chave como atributos às suas imagens. Os algoritmos então identificam e entendem esses parâmetros e aprendem de forma autônoma.
Classificação de imagem - A classificação de imagens envolve a atribuição de categorias ou rótulos predefinidos a imagens com base em seu conteúdo. Esse tipo de anotação é usado para treinar modelos de IA para reconhecer e categorizar imagens automaticamente.
Reconhecimento/detecção de objetos - O reconhecimento de objetos, ou detecção de objetos, é o processo de identificar e rotular objetos específicos dentro de uma imagem. Esse tipo de anotação é usado para treinar modelos de IA para localizar e reconhecer objetos em imagens ou vídeos do mundo real.
Segmentação – A segmentação de imagem envolve a divisão de uma imagem em vários segmentos ou regiões, cada um correspondendo a um objeto ou área de interesse específico. Esse tipo de anotação é usado para treinar modelos de IA para analisar imagens em nível de pixel, permitindo um reconhecimento de objetos e compreensão de cena mais precisos.
Anotação de Áudio
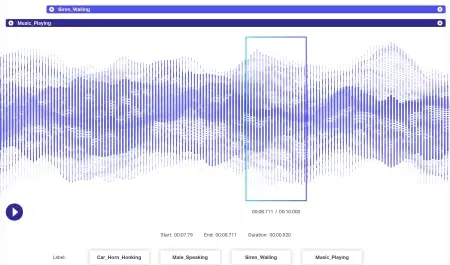
Os dados de áudio têm ainda mais dinâmicas anexadas a eles do que os dados de imagem. Vários fatores estão associados a um arquivo de áudio, incluindo, mas definitivamente não limitado a – idioma, demografia do falante, dialetos, humor, intenção, emoção, comportamento. Para que os algoritmos sejam eficientes no processamento, todos esses parâmetros devem ser identificados e marcados por técnicas como timestamp, rotulagem de áudio e muito mais. Além de pistas meramente verbais, instâncias não verbais como silêncio, respirações e até mesmo ruído de fundo podem ser anotadas para que os sistemas compreendam de forma abrangente.
Anotação de Vídeo

Enquanto uma imagem está parada, um vídeo é uma compilação de imagens que criam um efeito de objetos em movimento. Agora, cada imagem nesta compilação é chamada de quadro. No que diz respeito à anotação de vídeo, o processo envolve a adição de pontos-chave, polígonos ou caixas delimitadoras para anotar diferentes objetos no campo em cada quadro.
Quando esses quadros são costurados, o movimento, o comportamento, os padrões e muito mais podem ser aprendidos pelos modelos de IA em ação. É somente através anotação de vídeo que conceitos como localização, motion blur e rastreamento de objetos pudessem ser implementados em sistemas.
Anotação de Texto

Hoje, a maioria das empresas depende de dados baseados em texto para obter informações e insights exclusivos. Agora, o texto pode ser qualquer coisa, desde feedback do cliente em um aplicativo até uma menção na mídia social. E, ao contrário de imagens e vídeos que transmitem intenções diretas, o texto vem com muita semântica.
Como seres humanos, estamos sintonizados para entender o contexto de uma frase, o significado de cada palavra, frase ou frase, relacioná-las a uma determinada situação ou conversa e, então, perceber o significado holístico por trás de uma afirmação. As máquinas, por outro lado, não podem fazer isso em níveis precisos. Conceitos como sarcasmo, humor e outros elementos abstratos são desconhecidos para eles e é por isso que a rotulagem de dados de texto se torna mais difícil. É por isso que a anotação de texto tem alguns estágios mais refinados, como o seguinte:
Anotação Semântica – objetos, produtos e serviços são tornados mais relevantes por meio de marcação de frase-chave apropriada e parâmetros de identificação. Os chatbots também são feitos para imitar conversas humanas dessa maneira.
Anotação de intenção – a intenção de um usuário e a linguagem usada por eles são marcadas para que as máquinas entendam. Com isso, os modelos podem diferenciar uma solicitação de um comando, ou uma recomendação de uma reserva e assim por diante.
Anotação de sentimento – A anotação de sentimento envolve rotular dados textuais com o sentimento que eles transmitem, como positivo, negativo ou neutro. Esse tipo de anotação é comumente usado na análise de sentimento, onde os modelos de IA são treinados para entender e avaliar as emoções expressas no texto.

Anotação de Entidade – onde frases não estruturadas são marcadas para torná-las mais significativas e trazê-las para um formato que possa ser entendido por máquinas. Para que isso aconteça, dois aspectos estão envolvidos – reconhecimento de entidade nomeada e vinculação de entidade. O reconhecimento de entidade nomeada é quando nomes de lugares, pessoas, eventos, organizações e muito mais são marcados e identificados e a vinculação de entidades é quando essas tags são vinculadas a frases, frases, fatos ou opiniões que as seguem. Coletivamente, esses dois processos estabelecem a relação entre os textos associados e o enunciado que os envolve.
Categorização de texto – Frases ou parágrafos podem ser marcados e classificados com base em tópicos abrangentes, tendências, assuntos, opiniões, categorias (esportes, entretenimento e similares) e outros parâmetros.
Principais etapas no processo de rotulagem e anotação de dados
O processo de anotação de dados envolve uma série de etapas bem definidas para garantir rotulagem de dados precisa e de alta qualidade para aplicativos de aprendizado de máquina. Essas etapas abrangem todos os aspectos do processo, desde a coleta de dados até a exportação dos dados anotados para uso posterior.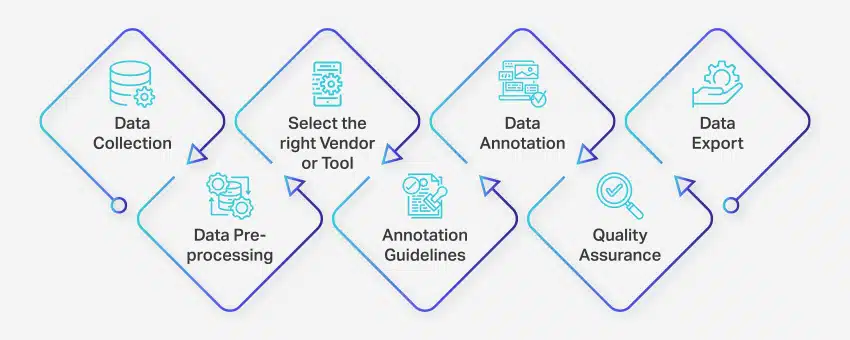
Veja como a anotação de dados ocorre:
- Coleção de dados: A primeira etapa no processo de anotação de dados é reunir todos os dados relevantes, como imagens, vídeos, gravações de áudio ou dados de texto, em um local centralizado.
- Pré-processamento de dados: Padronize e aprimore os dados coletados corrigindo imagens, formatando texto ou transcrevendo conteúdo de vídeo. O pré-processamento garante que os dados estejam prontos para anotação.
- Selecione o fornecedor ou ferramenta certa: Escolha uma ferramenta ou fornecedor de anotação de dados apropriado com base nos requisitos do seu projeto. As opções incluem plataformas como Nanonets para anotação de dados, V7 para anotação de imagens, Appen para anotação de vídeo e Nanonets para anotação de documentos.
- Diretrizes de anotação: Estabeleça diretrizes claras para anotadores ou ferramentas de anotação para garantir consistência e precisão ao longo do processo.
- Anotação: Rotule e marque os dados usando anotadores humanos ou software de anotação de dados, seguindo as diretrizes estabelecidas.
- Garantia de qualidade (GQ): Revise os dados anotados para garantir precisão e consistência. Empregue várias anotações cegas, se necessário, para verificar a qualidade dos resultados.
- Exportação de dados: Depois de concluir a anotação de dados, exporte os dados no formato necessário. Plataformas como Nanonets permitem a exportação contínua de dados para vários aplicativos de software de negócios.
Todo o processo de anotação de dados pode variar de alguns dias a várias semanas, dependendo do tamanho, complexidade e recursos disponíveis do projeto.
Recursos para ferramentas de anotação de dados e rotulagem de dados
As ferramentas de anotação de dados são fatores decisivos que podem fazer ou quebrar seu projeto de IA. Quando se trata de saídas e resultados precisos, a qualidade dos conjuntos de dados por si só não importa. Na verdade, as ferramentas de anotação de dados que você usa para treinar seus módulos de IA influenciam imensamente seus resultados.
É por isso que é essencial selecionar e usar a ferramenta de rotulagem de dados mais funcional e adequada que atenda às necessidades do seu negócio ou projeto. Mas o que é uma ferramenta de anotação de dados em primeiro lugar? Que finalidade serve? Existem tipos? Bem, vamos descobrir.
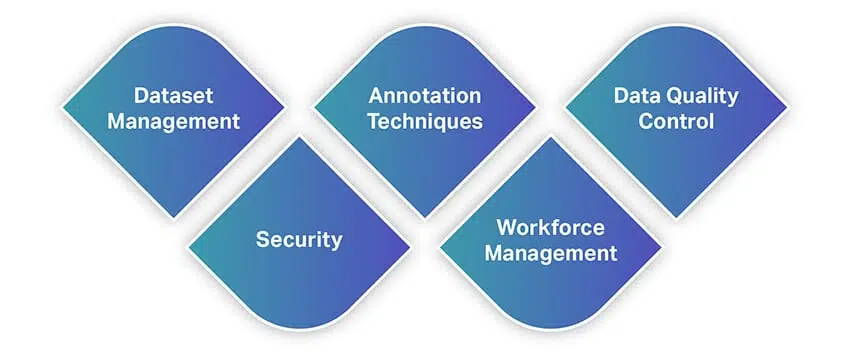
Semelhante a outras ferramentas, as ferramentas de anotação de dados oferecem uma ampla variedade de recursos e capacidades. Para dar uma ideia rápida dos recursos, aqui está uma lista de alguns dos recursos mais fundamentais que você deve procurar ao selecionar uma ferramenta de anotação de dados.
Gerenciamento de conjunto de dados
A ferramenta de anotação de dados que você pretende usar deve suportar os conjuntos de dados que você tem em mãos e permitir que você os importe para o software para rotulagem. Portanto, gerenciar seus conjuntos de dados é o principal recurso oferecido pelas ferramentas. As soluções contemporâneas oferecem recursos que permitem importar grandes volumes de dados sem problemas, permitindo simultaneamente organizar seus conjuntos de dados por meio de ações como classificar, filtrar, clonar, mesclar e muito mais.
Uma vez que a entrada de seus conjuntos de dados é feita, a seguir é exportá-los como arquivos utilizáveis. A ferramenta que você usa deve permitir que você salve seus conjuntos de dados no formato que você especificar para que você possa alimentá-los em seus modelos de ML.
Técnicas de Anotação
É para isso que uma ferramenta de anotação de dados é criada ou projetada. Uma ferramenta sólida deve oferecer uma variedade de técnicas de anotação para conjuntos de dados de todos os tipos. Isso ocorre a menos que você esteja desenvolvendo uma solução personalizada para suas necessidades. Sua ferramenta deve permitir que você anote vídeos ou imagens de visão computacional, áudio ou texto de NLPs e transcrições e muito mais. Refinando ainda mais, deve haver opções para usar caixas delimitadoras, segmentação semântica, cuboides, interpolação, análise de sentimentos, partes do discurso, solução de correferência e muito mais.
Para os não iniciados, também existem ferramentas de anotação de dados com inteligência artificial. Eles vêm com módulos de IA que aprendem de forma autônoma com os padrões de trabalho de um anotador e anotam imagens ou texto automaticamente. Tal
módulos podem ser usados para fornecer assistência incrível aos anotadores, otimizar anotações e até mesmo implementar verificações de qualidade.
Controle de qualidade de dados
Falando em verificações de qualidade, várias ferramentas de anotação de dados são lançadas com módulos de verificação de qualidade incorporados. Isso permite que os anotadores colaborem melhor com os membros da equipe e ajudem a otimizar os fluxos de trabalho. Com esse recurso, os anotadores podem marcar e rastrear comentários ou feedback em tempo real, rastrear identidades por trás de pessoas que fazem alterações em arquivos, restaurar versões anteriores, optar por rotular consenso e muito mais.
Segurança
Como você está trabalhando com dados, a segurança deve ser a prioridade mais alta. Você pode estar trabalhando em dados confidenciais, como os que envolvem detalhes pessoais ou propriedade intelectual. Portanto, sua ferramenta deve fornecer segurança absoluta em termos de onde os dados são armazenados e como são compartilhados. Ele deve fornecer ferramentas que limitem o acesso aos membros da equipe, impeçam downloads não autorizados e muito mais.
Além disso, os padrões e protocolos de segurança devem ser atendidos e cumpridos.
Gestão da força de trabalho
Uma ferramenta de anotação de dados também é uma espécie de plataforma de gerenciamento de projetos, onde as tarefas podem ser atribuídas aos membros da equipe, o trabalho colaborativo pode acontecer, as revisões são possíveis e muito mais. É por isso que sua ferramenta deve se adequar ao seu fluxo de trabalho e processo para otimizar a produtividade.
Além disso, a ferramenta também deve ter uma curva de aprendizado mínima, pois o processo de anotação de dados por si só é demorado. Não serve para nada gastar muito tempo simplesmente aprendendo a ferramenta. Portanto, deve ser intuitivo e contínuo para qualquer pessoa começar rapidamente.
Quais são os benefícios da anotação de dados?
A anotação de dados é crucial para otimizar os sistemas de aprendizado de máquina e oferecer experiências de usuário aprimoradas. Aqui estão alguns dos principais benefícios da anotação de dados:
- Eficiência de treinamento aprimorada: A rotulagem de dados ajuda os modelos de aprendizado de máquina a serem melhor treinados, melhorando a eficiência geral e produzindo resultados mais precisos.
- Maior precisão: Dados anotados com precisão garantem que os algoritmos possam se adaptar e aprender de forma eficaz, resultando em níveis mais altos de precisão em tarefas futuras.
- Intervenção humana reduzida: Ferramentas avançadas de anotação de dados diminuem significativamente a necessidade de intervenção manual, agilizando processos e reduzindo custos associados.
Assim, a anotação de dados contribui para sistemas de aprendizado de máquina mais eficientes e precisos, minimizando os custos e o esforço manual tradicionalmente necessários para treinar modelos de IA.
Para construir ou não construir uma ferramenta de anotação de dados
Um problema crítico e abrangente que pode surgir durante um projeto de anotação de dados ou rotulagem de dados é a escolha de construir ou comprar funcionalidades para esses processos. Isso pode surgir várias vezes em várias fases do projeto ou relacionado a diferentes segmentos do programa. Ao escolher entre construir um sistema internamente ou confiar em fornecedores, sempre há uma troca.

Como você provavelmente pode ver agora, a anotação de dados é um processo complexo. Ao mesmo tempo, é também um processo subjetivo. Ou seja, não há uma resposta única para a pergunta se você deve comprar ou construir uma ferramenta de anotação de dados. Muitos fatores precisam ser considerados e você precisa se fazer algumas perguntas para entender seus requisitos e perceber se realmente precisa comprar ou construir um.
Para tornar isso simples, aqui estão alguns dos fatores que você deve considerar.
Seu objetivo
O primeiro elemento que você precisa definir é o objetivo com seus conceitos de inteligência artificial e aprendizado de máquina.
- Por que você está implementando-os em seu negócio?
- Eles resolvem um problema do mundo real que seus clientes estão enfrentando?
- Eles estão fazendo algum processo de front-end ou back-end?
- Você usará a IA para introduzir novos recursos ou otimizar seu site, aplicativo ou módulo existente?
- O que seu concorrente está fazendo no seu segmento?
- Você tem casos de uso suficientes que precisam de intervenção de IA?
As respostas a elas agruparão seus pensamentos – que atualmente podem estar em todo o lugar – em um só lugar e lhe darão mais clareza.
Coleta de dados de IA / licenciamento
Os modelos de IA requerem apenas um elemento para funcionar – dados. Você precisa identificar de onde pode gerar grandes volumes de dados reais. Se sua empresa gera grandes volumes de dados que precisam ser processados para obter informações cruciais sobre negócios, operações, pesquisa de concorrentes, análise de volatilidade de mercado, estudo de comportamento do cliente e muito mais, você precisa de uma ferramenta de anotação de dados. No entanto, você também deve considerar o volume de dados que você gera. Como mencionado anteriormente, um modelo de IA é tão eficaz quanto a qualidade e a quantidade de dados que são alimentados. Portanto, suas decisões devem invariavelmente depender desse fator.
Se você não tiver os dados certos para treinar seus modelos de ML, os fornecedores podem ser bastante úteis, ajudando você com o licenciamento de dados do conjunto certo de dados necessários para treinar modelos de ML. Em alguns casos, parte do valor que o fornecedor traz envolverá tanto a proeza técnica quanto o acesso a recursos que promoverão o sucesso do projeto.
Orçamento
Outra condição fundamental que provavelmente influencia todos os fatores que estamos discutindo atualmente. A solução para a questão de construir ou comprar uma anotação de dados se torna fácil quando você entende se tem orçamento suficiente para gastar.
Complexidades de conformidade
 Os fornecedores podem ser extremamente úteis quando se trata de privacidade de dados e do manuseio correto de dados confidenciais. Um desses tipos de casos de uso envolve um hospital ou empresa relacionada à saúde que deseja utilizar o poder do aprendizado de máquina sem comprometer sua conformidade com HIPAA e outras regras de privacidade de dados. Mesmo fora da área médica, leis como o GDPR europeu estão reforçando o controle dos conjuntos de dados e exigindo mais vigilância por parte das partes interessadas corporativas.
Os fornecedores podem ser extremamente úteis quando se trata de privacidade de dados e do manuseio correto de dados confidenciais. Um desses tipos de casos de uso envolve um hospital ou empresa relacionada à saúde que deseja utilizar o poder do aprendizado de máquina sem comprometer sua conformidade com HIPAA e outras regras de privacidade de dados. Mesmo fora da área médica, leis como o GDPR europeu estão reforçando o controle dos conjuntos de dados e exigindo mais vigilância por parte das partes interessadas corporativas.
Manpower
A anotação de dados requer mão de obra qualificada para trabalhar, independentemente do tamanho, escala e domínio do seu negócio. Mesmo que você esteja gerando o mínimo de dados todos os dias, você precisa de especialistas em dados para trabalhar em seus dados para rotulagem. Então, agora, você precisa perceber se tem a mão de obra necessária. Se tiver, eles são qualificados nas ferramentas e técnicas necessárias ou precisam de qualificação? Se eles precisam de qualificação, você tem o orçamento para treiná-los em primeiro lugar?
Além disso, os melhores programas de anotação de dados e rotulagem de dados usam vários especialistas no assunto ou domínio e os segmentam de acordo com dados demográficos como idade, gênero e área de especialização – ou geralmente em termos dos idiomas localizados com os quais eles trabalharão. Isso é, novamente, onde nós da Shaip falamos sobre colocar as pessoas certas nos lugares certos, conduzindo assim os processos humanos corretos que levarão seus esforços programáticos ao sucesso.
Operações de pequenos e grandes projetos e limites de custo
Em muitos casos, o suporte do fornecedor pode ser mais uma opção para um projeto menor ou para fases de projeto menores. Quando os custos são controláveis, a empresa pode se beneficiar da terceirização para tornar os projetos de anotação ou rotulagem de dados mais eficientes.
As empresas também podem observar limites importantes – onde muitos fornecedores vinculam o custo à quantidade de dados consumidos ou a outros benchmarks de recursos. Por exemplo, digamos que uma empresa se inscreveu com um fornecedor para fazer a entrada de dados tediosa necessária para configurar conjuntos de teste.
Pode haver um limite oculto no contrato em que, por exemplo, o parceiro de negócios tenha que retirar outro bloco de armazenamento de dados da AWS ou algum outro componente de serviço da Amazon Web Services ou algum outro fornecedor terceirizado. Eles repassam isso para o cliente na forma de custos mais altos, e isso coloca o preço fora do alcance do cliente.
Nesses casos, medir os serviços que você obtém dos fornecedores ajuda a manter o projeto acessível. Ter o escopo certo no lugar garantirá que os custos do projeto não excedam o que é razoável ou viável para a empresa em questão.
Alternativas de código aberto e freeware
 Algumas alternativas ao suporte total do fornecedor envolvem o uso de software de código aberto, ou mesmo freeware, para realizar projetos de anotação de dados ou rotulagem. Aqui há uma espécie de meio termo em que as empresas não criam tudo do zero, mas também evitam depender muito de fornecedores comerciais.
Algumas alternativas ao suporte total do fornecedor envolvem o uso de software de código aberto, ou mesmo freeware, para realizar projetos de anotação de dados ou rotulagem. Aqui há uma espécie de meio termo em que as empresas não criam tudo do zero, mas também evitam depender muito de fornecedores comerciais.
A mentalidade de “faça você mesmo” do código aberto é em si uma espécie de compromisso – engenheiros e pessoas internas podem tirar proveito da comunidade de código aberto, onde bases de usuários descentralizadas oferecem seus próprios tipos de suporte de base. Não será como o que você recebe de um fornecedor – você não terá assistência fácil 24 horas por dia, 7 dias por semana, ou respostas a perguntas sem fazer uma pesquisa interna – mas o preço é menor.
Então, a grande questão – Quando você deve comprar uma ferramenta de anotação de dados:
Tal como acontece com muitos tipos de projetos de alta tecnologia, esse tipo de análise – quando construir e quando comprar – requer reflexão dedicada e consideração de como esses projetos são adquiridos e gerenciados. Os desafios que a maioria das empresas enfrenta relacionados a projetos de IA/ML ao considerar a opção “construir” é que não se trata apenas das partes de construção e desenvolvimento do projeto. Muitas vezes, há uma enorme curva de aprendizado para chegar ao ponto em que o verdadeiro desenvolvimento de IA/ML pode ocorrer. Com novas equipes e iniciativas de IA/ML, o número de “desconhecidos desconhecidos” supera em muito o número de “desconhecidos conhecidos”.
| Construa | Comprar |
|---|---|
Prós:
| Prós:
|
Contras:
| Contras:
|
Para tornar as coisas ainda mais simples, considere os seguintes aspectos:
- quando você trabalha em grandes volumes de dados
- quando você trabalha em diversas variedades de dados
- quando as funcionalidades associadas aos seus modelos ou soluções podem mudar ou evoluir no futuro
- quando você tem um caso de uso vago ou genérico
- quando você precisa de uma ideia clara sobre as despesas envolvidas na implantação de uma ferramenta de anotação de dados
- e quando você não tem a força de trabalho certa ou especialistas qualificados para trabalhar nas ferramentas e está procurando uma curva de aprendizado mínima
Se suas respostas foram opostas a esses cenários, você deve se concentrar na construção de sua ferramenta.
Como escolher a ferramenta de anotação de dados certa para o seu projeto
Se você está lendo isso, essas ideias parecem empolgantes e são definitivamente mais fáceis de dizer do que de fazer. Então, como é possível aproveitar a infinidade de ferramentas de anotação de dados já existentes? Portanto, o próximo passo envolvido é considerar os fatores associados à escolha da ferramenta de anotação de dados correta.
Ao contrário de alguns anos atrás, o mercado evoluiu com toneladas de ferramentas de anotação de dados em prática hoje. As empresas têm mais opções na escolha de um com base em suas necessidades distintas. Mas cada ferramenta vem com seu próprio conjunto de prós e contras. Para tomar uma decisão sábia, um caminho objetivo deve ser tomado além dos requisitos subjetivos.
Vejamos alguns dos fatores cruciais que você deve considerar no processo.
Definindo seu caso de uso
Para selecionar a ferramenta de anotação de dados correta, você precisa definir seu caso de uso. Você deve perceber se seu requisito envolve texto, imagem, vídeo, áudio ou uma mistura de todos os tipos de dados. Existem ferramentas independentes que você pode comprar e ferramentas holísticas que permitem executar diversas ações em conjuntos de dados.
As ferramentas hoje são intuitivas e oferecem opções em termos de facilidades de armazenamento (rede, local ou nuvem), técnicas de anotação (áudio, imagem, 3D e mais) e uma série de outros aspectos. Você pode escolher uma ferramenta com base em seus requisitos específicos.
Estabelecendo Padrões de Controle de Qualidade
 Esse é um fator crucial a ser considerado, pois o objetivo e a eficiência de seus modelos de IA dependem dos padrões de qualidade que você estabelece. Assim como uma auditoria, você precisa realizar verificações de qualidade dos dados que alimenta e dos resultados obtidos para entender se seus modelos estão sendo treinados da maneira certa e para os propósitos certos. No entanto, a questão é como você pretende estabelecer padrões de qualidade?
Esse é um fator crucial a ser considerado, pois o objetivo e a eficiência de seus modelos de IA dependem dos padrões de qualidade que você estabelece. Assim como uma auditoria, você precisa realizar verificações de qualidade dos dados que alimenta e dos resultados obtidos para entender se seus modelos estão sendo treinados da maneira certa e para os propósitos certos. No entanto, a questão é como você pretende estabelecer padrões de qualidade?
Tal como acontece com muitos tipos diferentes de trabalhos, muitas pessoas podem fazer uma anotação e marcação de dados, mas o fazem com vários graus de sucesso. Ao solicitar um serviço, você não verifica automaticamente o nível de controle de qualidade. É por isso que os resultados variam.
Então, você quer implantar um modelo de consenso, onde os anotadores oferecem feedback sobre a qualidade e as medidas corretivas são tomadas instantaneamente? Ou você prefere revisão de amostra, padrões-ouro ou interseção sobre modelos de união?
O melhor plano de compra garantirá que o controle de qualidade esteja em vigor desde o início, definindo padrões antes que qualquer contrato final seja acordado. Ao estabelecer isso, você também não deve ignorar as margens de erro. A intervenção manual não pode ser completamente evitada, pois os sistemas tendem a produzir erros em taxas de até 3%. Isso dá trabalho na frente, mas vale a pena.
Quem anotará seus dados?
O próximo fator importante depende de quem anota seus dados. Você pretende ter uma equipe interna ou prefere terceirizar? Se você estiver terceirizando, existem medidas legais e de conformidade que você precisa considerar devido às preocupações de privacidade e confidencialidade associadas aos dados. E se você tem uma equipe interna, qual é a eficiência deles em aprender uma nova ferramenta? Qual é o seu time-to-market com seu produto ou serviço? Você tem as métricas e equipes de qualidade certas para aprovar os resultados?
O vendedor vs. Debate de parceiros
 A anotação de dados é um processo colaborativo. Envolve dependências e complexidades como interoperabilidade. Isso significa que certas equipes estão sempre trabalhando em conjunto e uma das equipes pode ser seu fornecedor. É por isso que o fornecedor ou parceiro selecionado é tão importante quanto a ferramenta que você usa para rotulagem de dados.
A anotação de dados é um processo colaborativo. Envolve dependências e complexidades como interoperabilidade. Isso significa que certas equipes estão sempre trabalhando em conjunto e uma das equipes pode ser seu fornecedor. É por isso que o fornecedor ou parceiro selecionado é tão importante quanto a ferramenta que você usa para rotulagem de dados.
Com esse fator, aspectos como a capacidade de manter seus dados e intenções confidenciais, a intenção de aceitar e trabalhar no feedback, ser proativo em termos de requisições de dados, flexibilidade nas operações e muito mais devem ser considerados antes de apertar a mão de um fornecedor ou parceiro . Incluímos flexibilidade porque os requisitos de anotação de dados nem sempre são lineares ou estáticos. Eles podem mudar no futuro à medida que você expande ainda mais seus negócios. Se você estiver lidando apenas com dados baseados em texto, convém anotar dados de áudio ou vídeo à medida que dimensiona e seu suporte deve estar pronto para expandir seus horizontes com você.
Envolvimento do Fornecedor
Uma das maneiras de avaliar o envolvimento do fornecedor é o suporte que você receberá.
Qualquer plano de compra deve levar em consideração esse componente. Como será o suporte no chão? Quem serão as partes interessadas e as pessoas pontuais em ambos os lados da equação?
Há também tarefas concretas que precisam especificar qual é (ou será) o envolvimento do fornecedor. Para um projeto de anotação de dados ou rotulagem de dados em particular, o fornecedor fornecerá ativamente os dados brutos ou não? Quem atuará como especialistas no assunto e quem os empregará como funcionários ou contratados independentes?
Estudos de Caso
Aqui estão alguns exemplos de estudos de caso específicos que abordam como a anotação de dados e a rotulagem de dados realmente funcionam no terreno. Na Shaip, temos o cuidado de fornecer os mais altos níveis de qualidade e resultados superiores em anotação de dados e rotulagem de dados.
Grande parte da discussão acima sobre realizações padrão para anotação de dados e rotulagem de dados revela como abordamos cada projeto e o que oferecemos às empresas e partes interessadas com as quais trabalhamos.
Materiais de estudo de caso que demonstrarão como isso funciona:

Em um projeto de licenciamento de dados clínicos, a equipe Shaip processou mais de 6,000 horas de áudio, removendo todas as informações de saúde protegidas (PHI) e deixando o conteúdo compatível com HIPAA para modelos de reconhecimento de fala de saúde para trabalhar.
Nesse tipo de caso, são os critérios e a classificação das conquistas que são importantes. Os dados brutos estão na forma de áudio e há a necessidade de desidentificar as partes. Por exemplo, ao usar a análise NER, o objetivo duplo é desidentificar e anotar o conteúdo.
Outro estudo de caso envolve uma dados de treinamento de IA de conversação projeto que concluímos com 3,000 linguistas trabalhando em um período de 14 semanas. Isso levou à produção de dados de treinamento em 27 idiomas, a fim de desenvolver assistentes digitais multilíngues capazes de lidar com interações humanas em uma ampla seleção de idiomas nativos.
Neste estudo de caso em particular, a necessidade de colocar a pessoa certa na cadeira certa era evidente. O grande número de especialistas no assunto e operadores de entrada de conteúdo significava que havia a necessidade de organização e simplificação de procedimentos para realizar o projeto em um cronograma específico. Nossa equipe conseguiu superar o padrão do setor por uma ampla margem, otimizando a coleta de dados e os processos subsequentes.
Outros tipos de estudos de caso envolvem coisas como treinamento de bot e anotação de texto para aprendizado de máquina. Novamente, em um formato de texto, ainda é importante tratar as partes identificadas de acordo com as leis de privacidade e classificar os dados brutos para obter os resultados desejados.
Em outras palavras, ao trabalhar em vários tipos e formatos de dados, a Shaip demonstrou o mesmo sucesso vital ao aplicar os mesmos métodos e princípios a dados brutos e cenários de negócios de licenciamento de dados.