
Este método ajuda a IA a saber quando evitar certas questões. Aprende a rejeitar solicitações que envolvam conteúdo prejudicial, como violência ou discriminação.
Um exemplo bem conhecido de modelo usando RLHF é ChatGPT da OpenAI. Este modelo utiliza feedback humano para melhorar as respostas e torná-las mais relevantes e responsáveis.
Etapas de aprendizagem por reforço com feedback humano
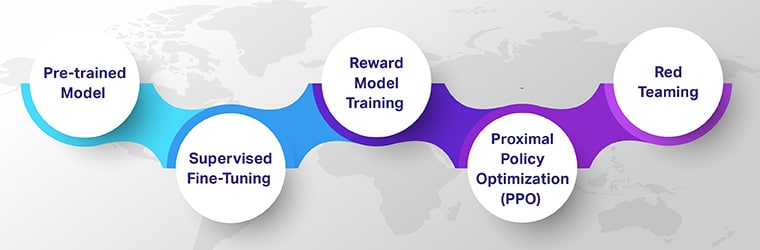
O Aprendizado por Reforço com Feedback Humano (RLHF) garante que os modelos de IA sejam tecnicamente proficientes, eticamente sólidos e contextualmente relevantes. Analise as cinco etapas principais do RLHF que exploram como elas contribuem para a criação de sistemas sofisticados de IA guiados por humanos.
Começando com um modelo pré-treinado
A jornada RLHF começa com um modelo pré-treinado, uma etapa fundamental no aprendizado de máquina Human-in-the-Loop. Inicialmente treinados em extensos conjuntos de dados, esses modelos possuem uma ampla compreensão da linguagem ou de outras tarefas básicas, mas carecem de especialização.
Os desenvolvedores começam com um modelo pré-treinado e obtêm uma vantagem significativa. Esses modelos já foram aprendidos a partir de grandes quantidades de dados. Isso os ajuda a economizar tempo e recursos na fase inicial de treinamento. Esta etapa prepara o terreno para um treinamento mais focado e específico que se segue.
Ajuste fino supervisionado
A segunda etapa envolve o ajuste fino supervisionado, onde o modelo pré-treinado passa por treinamento adicional em uma tarefa ou domínio específico. Esta etapa é caracterizada pelo uso de dados rotulados, o que ajuda o modelo a gerar resultados mais precisos e contextualmente relevantes.
Este processo de ajuste fino é um excelente exemplo de treinamento em IA guiado por humanos, onde o julgamento humano desempenha um papel importante na orientação da IA para os comportamentos e respostas desejados. Os formadores devem selecionar e apresentar cuidadosamente dados específicos do domínio para garantir que a IA se adapta às nuances e requisitos específicos da tarefa em questão.
Treinamento de modelo de recompensa
Na terceira etapa, você treina um modelo separado para reconhecer e recompensar os resultados desejáveis gerados pela IA. Esta etapa é fundamental para o aprendizado de IA baseado em feedback.
O modelo de recompensa avalia os resultados da IA. Ele atribui pontuações com base em critérios como relevância, precisão e alinhamento com os resultados desejados. Essas pontuações atuam como feedback e orientam a IA na produção de respostas de maior qualidade. Este processo permite uma compreensão mais matizada de tarefas complexas ou subjetivas onde instruções explícitas podem ser insuficientes para um treinamento eficaz.
Aprendizagem por Reforço via Otimização de Política Proximal (PPO)
Em seguida, a IA passa por Reinforcement Learning via Proximal Policy Optimization (PPO), uma abordagem algorítmica sofisticada em aprendizado de máquina interativo.
O PPO permite que a IA aprenda com a interação direta com seu ambiente. Ele refina seu processo de tomada de decisão por meio de recompensas e penalidades. Este método é particularmente eficaz na aprendizagem e adaptação em tempo real, pois ajuda a IA a compreender as consequências das suas ações em vários cenários.
O PPO é fundamental para ensinar a IA a navegar em ambientes complexos e dinâmicos onde os resultados desejados podem evoluir ou ser difíceis de definir.
Teaming vermelho
A etapa final envolve testes rigorosos do sistema de IA no mundo real. Aqui, um grupo diversificado de avaliadores, conhecido como 'Equipa vermelha,'desafie a IA com vários cenários. Eles testam sua capacidade de responder de forma precisa e adequada. Esta fase garante que a IA possa lidar com aplicações do mundo real e situações imprevisíveis.
O Red Teaming testa a proficiência técnica e a solidez ética e contextual da IA. Eles garantem que ela opere dentro de limites morais e culturais aceitáveis.
Ao longo destas etapas, a RLHF enfatiza a importância do envolvimento humano em todas as fases do desenvolvimento da IA. Desde orientar o treinamento inicial com dados cuidadosamente selecionados até fornecer feedback diferenciado e testes rigorosos no mundo real, a contribuição humana é essencial para a criação de sistemas de IA que sejam inteligentes, responsáveis e sintonizados com os valores e a ética humanos.
Conclusão
O Aprendizado por Reforço com Feedback Humano (RLHF) mostra uma nova era na IA, pois combina insights humanos com aprendizado de máquina para sistemas de IA mais éticos e precisos.
A RLHF promete tornar a IA mais empática, inclusiva e inovadora. Pode abordar preconceitos e melhorar a resolução de problemas. O objetivo é transformar áreas como saúde, educação e atendimento ao cliente.
No entanto, o aperfeiçoamento desta abordagem requer esforços contínuos para garantir a eficácia, a justiça e o alinhamento ético.


