
Você já se perguntou como chatbots e assistentes virtuais acordam quando você diz 'Hey Siri' ou 'Alexa'? É por causa da coleta de enunciados de texto ou acionadores de palavras embutidos no software que aciona o sistema assim que ouve a palavra de ativação programada.
No entanto, o processo geral de criação de sons e dados de enunciados não é tão simples. É um processo que deve ser realizado com a técnica certa para obter os resultados desejados. Portanto, este blog compartilhará o caminho para criar bons enunciados/palavras-gatilho que funcionem perfeitamente com sua IA conversacional.
O que são enunciados?
Os enunciados podem ser referidos como frases ou palavras-chave usadas para ativar um modelo artificialmente inteligente. Quando seu modelo de IA detecta sua palavra de ativação, ele inicia automaticamente a gravação da próxima solicitação do usuário e responde com uma ação ou resposta adequada.
O Utterance usa o conceito de aprendizado profundo para ensinar o software a reconhecer palavras de ativação. Depois que a palavra de ativação ativa o software, o sistema começa a capturar, decodificar e atender à solicitação. Quando não está em uso, o sistema continua escutando passivamente as palavras de gatilho.
Para que seu software de IA obtenha resultados precisos, é essencial capturar uma infinidade de enunciados diferentes para cada intenção. Isso ajuda no melhor treinamento para o modelo de IA.
[Leia também: Gostaria de saber como Siri e Alexa entendem você?]
Pontos a serem lembrados ao criar um repositório de enunciados
Agora que sabemos que o treinamento é importante para os modelos de IA, a próxima coisa a saber é como fornecer enunciados aos modelos de IA. Normalmente, um repositório de enunciados é criado para treinar IAs conversacionais.
No entanto, há várias coisas a serem lembradas ao construir repositórios de enunciados. A seguir estão as coisas a considerar:
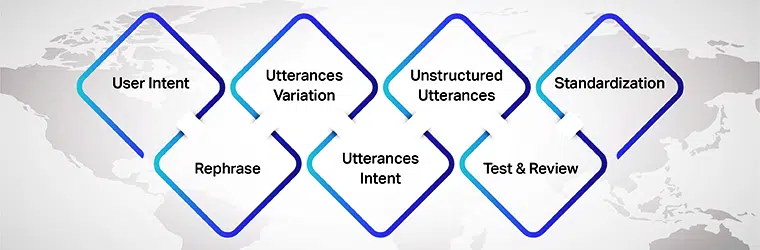
Intenção do usuário
Principalmente ao preparar enunciados para seu modelo de IA, certifique-se de entender a intenção do usuário para a qual você está desenvolvendo os conjuntos de dados. Você precisa descobrir os diferentes enunciados que os usuários podem inserir enquanto conversam com o modelo de IA.
Variação de enunciados
As variações são uma parte essencial desse processo, pois quanto mais variações para cada intenção, melhores resultados você alcançará. Portanto, certifique-se de criar várias variações de enunciados do usuário. Você pode fazê-lo por
- Criar frases curtas, médias e grandes para as mesmas frases.
- Alterar as palavras e o comprimento das frases.
- Usando palavras únicas.
- Pluralização das frases.
- Misturando a gramática.



