
A Inteligência Artificial está revolucionando a indústria da música, oferecendo ferramentas automatizadas de composição, masterização e performance. Os algoritmos de IA geram novas composições, preveem sucessos e personalizam a experiência do ouvinte, transformando a produção, distribuição e consumo de música. Essa tecnologia emergente apresenta oportunidades empolgantes e dilemas éticos desafiadores.
Os modelos de aprendizado de máquina (ML) exigem dados de treinamento para funcionar de maneira eficaz, pois um compositor precisa de notas musicais para escrever uma sinfonia. No mundo da música, onde melodia, ritmo e emoção se entrelaçam, a importância de dados de treinamento de qualidade não pode ser exagerada. É a espinha dorsal do desenvolvimento de modelos de ML de música robustos e precisos para análise preditiva, classificação de gênero ou transcrição automática.
Dados, a força vital dos modelos de ML
O aprendizado de máquina é inerentemente orientado a dados. Esses modelos computacionais aprendem padrões a partir dos dados, permitindo-lhes fazer previsões ou tomar decisões. Para modelos de ML de música, os dados de treinamento geralmente vêm em faixas de música digitalizadas, letras, metadados ou uma combinação desses elementos. A qualidade, quantidade e diversidade desses dados impactam significativamente a eficácia do modelo.

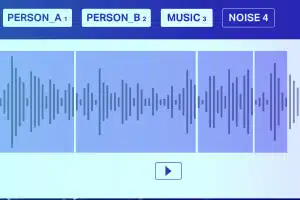
Rotulagem de Som
Com a rotulagem de som, os anotadores de dados recebem uma gravação e precisam separar todos os sons necessários e rotulá-los. Por exemplo, podem ser determinadas palavras-chave ou o som de um instrumento musical específico.

Classificação de música
Os anotadores de dados podem marcar gêneros ou instrumentos nesse tipo de anotação de áudio. A classificação de música é muito útil para organizar bibliotecas de música e melhorar as recomendações do usuário.

Segmentação de nível fonético
Rótulo e classificação de segmentos fonéticos nas formas de onda e espectrogramas de gravações de indivíduos cantando a capella.
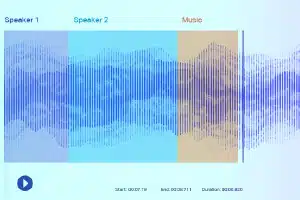
Classificação sonora
Com exceção do silêncio/ruído branco, um arquivo de áudio geralmente consiste nos seguintes tipos de som: Fala, Babble, Music e Noise. Anote notas musicais com precisão para maior precisão.
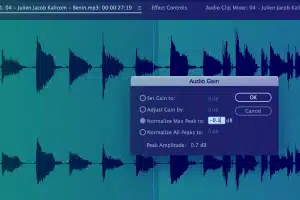
Captura de informações de metadados
Capture informações importantes, como hora de início, hora de término, ID do segmento, nível de volume, tipo de som principal, código do idioma, ID do alto-falante e outras convenções de transcrição, etc.


