

O que são grandes modelos de linguagem?
Os Large Language Models (LLMs) são sistemas avançados de inteligência artificial (IA) projetados para processar, entender e gerar texto semelhante ao humano. Eles são baseados em técnicas de aprendizado profundo e treinados em grandes conjuntos de dados, geralmente contendo bilhões de palavras de diversas fontes, como sites, livros e artigos. Este treinamento extensivo permite que os LLMs compreendam as nuances da linguagem, gramática, contexto e até mesmo alguns aspectos do conhecimento geral.
Alguns LLMs populares, como o GPT-3 da OpenAI, empregam um tipo de rede neural chamada transformador, que permite lidar com tarefas complexas de linguagem com proficiência notável. Esses modelos podem executar uma ampla gama de tarefas, como:
- Respondendo a perguntas
- Resumindo o texto
- Traduzindo idiomas
- Gerando conteúdo
- Mesmo participando de conversas interativas com os usuários
À medida que os LLMs continuam a evoluir, eles têm grande potencial para aprimorar e automatizar vários aplicativos em todos os setores, desde atendimento ao cliente e criação de conteúdo até educação e pesquisa. No entanto, eles também levantam preocupações éticas e sociais, como comportamento tendencioso ou uso indevido, que precisam ser abordados à medida que a tecnologia avança.

Exemplos populares de modelos de linguagem grandes
Aqui estão alguns exemplos proeminentes de LLMs amplamente utilizados em diferentes verticais da indústria:
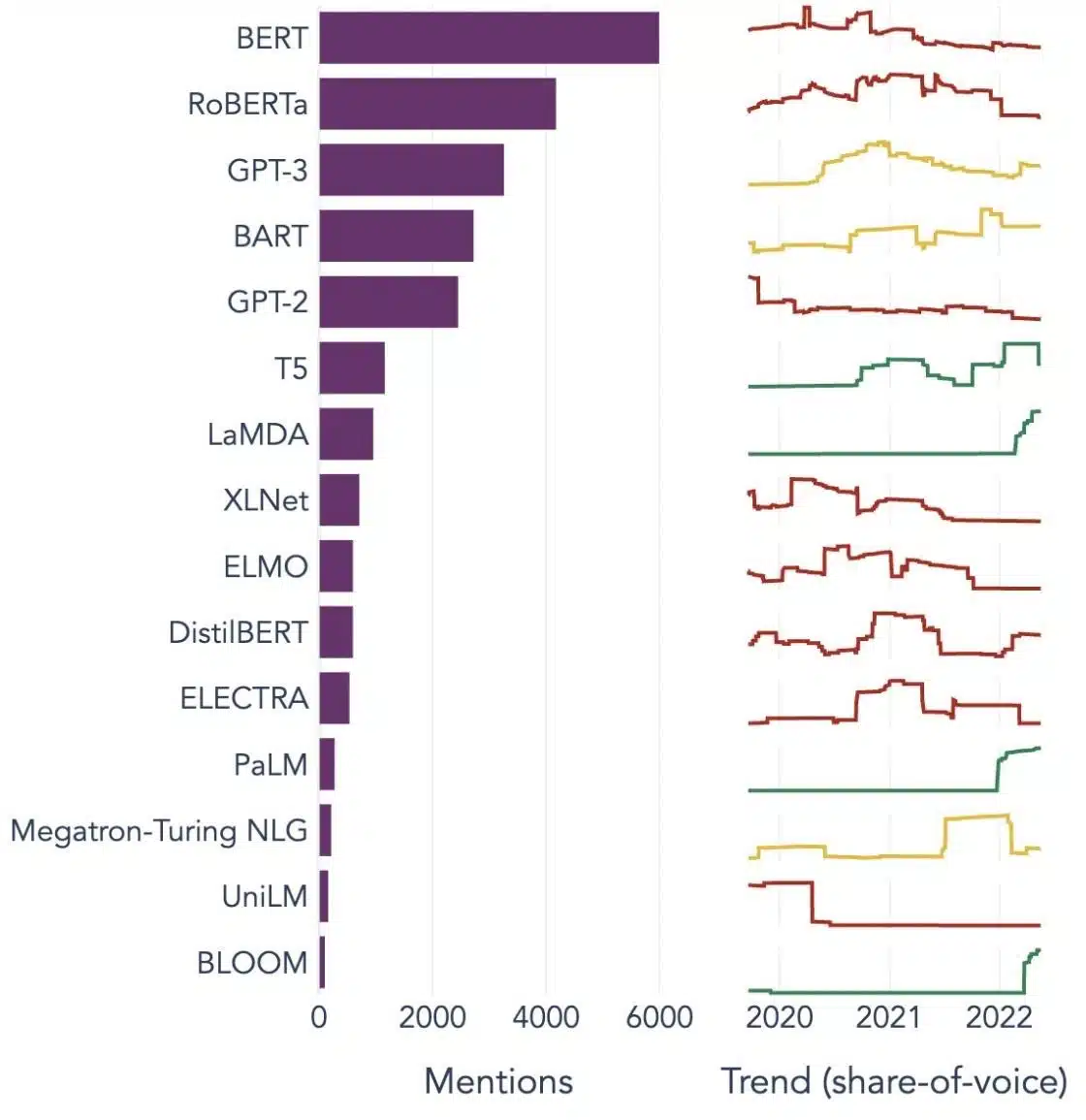
Fonte da imagem: Em direção à ciência de dados
Como os modelos LLM são treinados?
O treinamento de modelos de linguagem grandes (LLMs) é uma façanha que envolve várias etapas cruciais. Aqui está um resumo passo a passo simplificado do processo:
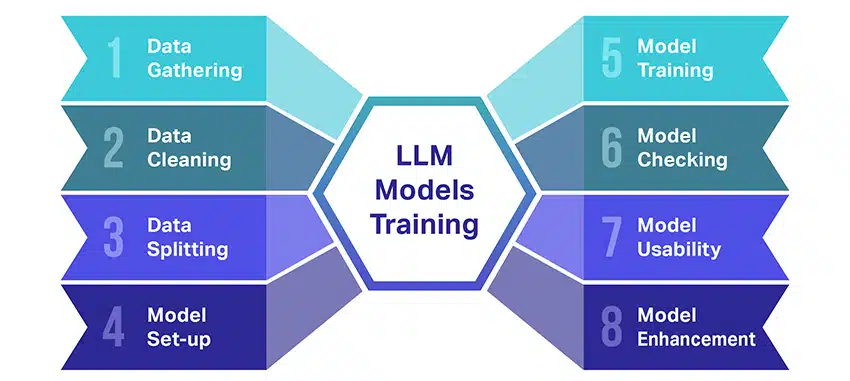
- Coletando dados de texto: O treinamento de um LLM começa com a coleta de uma grande quantidade de dados de texto. Esses dados podem vir de livros, sites, artigos ou plataformas de mídia social. O objetivo é capturar a rica diversidade da linguagem humana.
- Limpando os dados: Os dados de texto bruto são então organizados em um processo chamado pré-processamento. Isso inclui tarefas como remover caracteres indesejados, dividir o texto em partes menores chamadas tokens e colocar tudo em um formato com o qual o modelo possa trabalhar.
- Dividindo os dados: Em seguida, os dados limpos são divididos em dois conjuntos. Um conjunto, os dados de treinamento, será usado para treinar o modelo. O outro conjunto, os dados de validação, serão usados posteriormente para testar o desempenho do modelo.
- Configurando o modelo: A estrutura do LLM, conhecida como arquitetura, é então definida. Isso envolve selecionar o tipo de rede neural e decidir sobre vários parâmetros, como o número de camadas e unidades ocultas na rede.
- Treinando o Modelo: O treinamento real agora começa. O modelo LLM aprende observando os dados de treinamento, fazendo previsões com base no que aprendeu até agora e ajustando seus parâmetros internos para reduzir a diferença entre suas previsões e os dados reais.
- Verificando o modelo: O aprendizado do modelo LLM é verificado usando os dados de validação. Isso ajuda a ver o desempenho do modelo e a ajustar as configurações do modelo para um melhor desempenho.
- Usando o modelo: Após treinamento e avaliação, o modelo LLM está pronto para uso. Agora ele pode ser integrado a aplicativos ou sistemas onde gerará texto com base nas novas entradas fornecidas.
- Melhorando o modelo: Finalmente, sempre há espaço para melhorias. O modelo LLM pode ser refinado ao longo do tempo, usando dados atualizados ou ajustando as configurações com base no feedback e no uso do mundo real.
Lembre-se, esse processo requer recursos computacionais significativos, como unidades de processamento poderosas e grande capacidade de armazenamento, além de conhecimento especializado em aprendizado de máquina. É por isso que geralmente é feito por organizações ou empresas de pesquisa dedicadas com acesso à infraestrutura e experiência necessárias.
O LLM depende de aprendizado supervisionado ou não supervisionado?
Grandes modelos de linguagem geralmente são treinados usando um método chamado aprendizado supervisionado. Em termos simples, isso significa que eles aprendem com exemplos que mostram as respostas corretas.
 Imagine que você está ensinando palavras a uma criança, mostrando-lhes imagens. Você mostra a eles a foto de um gato e diz “gato” e eles aprendem a associar essa foto à palavra. É assim que funciona o aprendizado supervisionado. O modelo recebe muito texto (as “imagens”) e as saídas correspondentes (as “palavras”), e aprende a combiná-los.
Imagine que você está ensinando palavras a uma criança, mostrando-lhes imagens. Você mostra a eles a foto de um gato e diz “gato” e eles aprendem a associar essa foto à palavra. É assim que funciona o aprendizado supervisionado. O modelo recebe muito texto (as “imagens”) e as saídas correspondentes (as “palavras”), e aprende a combiná-los.
Portanto, se você alimentar um LLM com uma frase, ele tentará prever a próxima palavra ou frase com base no que aprendeu com os exemplos. Assim, ele aprende a gerar um texto que faça sentido e se encaixe no contexto.
Dito isso, às vezes os LLMs também usam um pouco de aprendizado não supervisionado. É como deixar a criança explorar uma sala cheia de brinquedos diferentes e aprender sobre eles por conta própria. O modelo analisa dados não rotulados, padrões de aprendizado e estruturas sem receber as respostas “certas”.
O aprendizado supervisionado emprega dados rotulados com entradas e saídas, em contraste com o aprendizado não supervisionado, que não usa dados de saída rotulados.
Em poucas palavras, os LLMs são treinados principalmente usando aprendizado supervisionado, mas também podem usar aprendizado não supervisionado para aprimorar suas capacidades, como para análise exploratória e redução de dimensionalidade.
Qual é o volume de dados (em GB) necessário para treinar um grande modelo de linguagem?
O mundo de possibilidades para reconhecimento de dados de fala e aplicativos de voz é imenso, e eles estão sendo usados em diversos setores para uma infinidade de aplicações.
O treinamento de um grande modelo de linguagem não é um processo único para todos, especialmente quando se trata dos dados necessários. Depende de um monte de coisas:
- O desenho do modelo.
- Que trabalho precisa fazer?
- O tipo de dados que você está usando.
- Quão bem você quer que ele funcione?
Dito isso, o treinamento de LLMs geralmente requer uma grande quantidade de dados de texto. Mas de que massa estamos falando? Bem, pense muito além dos gigabytes (GB). Normalmente, estamos analisando terabytes (TB) ou até mesmo petabytes (PB) de dados.
Considere o GPT-3, um dos maiores LLMs do mercado. É treinado em 570 GB de dados de texto. LLMs menores podem precisar de menos – talvez 10-20 GB ou até 1 GB de gigabytes – mas ainda é muito.

Mas não se trata apenas do tamanho dos dados. A qualidade também importa. Os dados precisam ser limpos e variados para ajudar o modelo a aprender de forma eficaz. E você não pode esquecer outras peças-chave do quebra-cabeça, como o poder de computação de que precisa, os algoritmos que usa para treinamento e a configuração de hardware que possui. Todos esses fatores desempenham um papel importante no treinamento de um LLM.
A ascensão de grandes modelos de linguagem: por que eles são importantes
Os LLMs não são mais apenas um conceito ou um experimento. Eles estão cada vez mais desempenhando um papel crítico em nosso cenário digital. Mas por que isso está acontecendo? O que torna esses LLMs tão importantes? Vamos nos aprofundar em alguns fatores-chave.
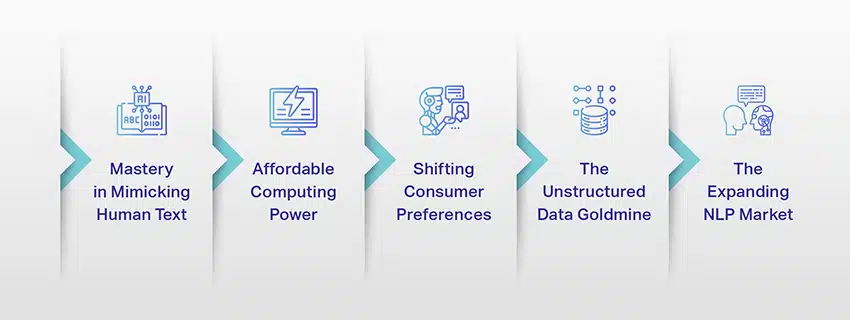
Domínio em imitar texto humano
Os LLMs transformaram a maneira como lidamos com tarefas baseadas em linguagem. Construídos com algoritmos robustos de aprendizado de máquina, esses modelos são equipados com a capacidade de entender as nuances da linguagem humana, incluindo contexto, emoção e até sarcasmo, até certo ponto. Esta capacidade de imitar a linguagem humana não é uma mera novidade, tem implicações significativas.
As habilidades avançadas de geração de texto dos LLMs podem aprimorar tudo, desde a criação de conteúdo até as interações de atendimento ao cliente.
Imagine ser capaz de fazer uma pergunta complexa a um assistente digital e obter uma resposta que não apenas faça sentido, mas também seja coerente, relevante e entregue em tom de conversa. É isso que os LLMs estão permitindo. Eles estão alimentando uma interação homem-máquina mais intuitiva e envolvente, enriquecendo as experiências do usuário e democratizando o acesso à informação.
Poder de computação acessível
A ascensão dos LLMs não teria sido possível sem desenvolvimentos paralelos no campo da computação. Mais especificamente, a democratização dos recursos computacionais desempenhou um papel significativo na evolução e adoção dos LLMs.
As plataformas baseadas em nuvem estão oferecendo acesso sem precedentes a recursos de computação de alto desempenho. Dessa forma, até mesmo organizações de pequena escala e pesquisadores independentes podem treinar modelos sofisticados de aprendizado de máquina.
Além disso, as melhorias nas unidades de processamento (como GPUs e TPUs), combinadas com o surgimento da computação distribuída, tornaram viável o treinamento de modelos com bilhões de parâmetros. Essa maior acessibilidade do poder de computação está permitindo o crescimento e o sucesso dos LLMs, levando a mais inovações e aplicações no campo.
Mudança nas preferências do consumidor
Os consumidores de hoje não querem apenas respostas; eles querem interações envolventes e relacionáveis. À medida que mais pessoas crescem usando a tecnologia digital, fica evidente que aumenta a necessidade de uma tecnologia que pareça mais natural e humana. Os LLMs oferecem uma oportunidade inigualável de atender a essas expectativas. Ao gerar texto semelhante ao humano, esses modelos podem criar experiências digitais envolventes e dinâmicas, que podem aumentar a satisfação e a fidelidade do usuário. Sejam chatbots de IA fornecendo atendimento ao cliente ou assistentes de voz fornecendo atualizações de notícias, os LLMs estão inaugurando uma era de IA que nos entende melhor.
A mina de ouro dos dados não estruturados
Dados não estruturados, como e-mails, postagens em mídias sociais e avaliações de clientes, são um tesouro de insights. Estima-se que mais de 80% dos dados corporativos é desestruturado e cresce a uma taxa de 55% por ano. Esses dados são uma mina de ouro para as empresas, se aproveitados adequadamente.
Os LLMs entram em jogo aqui, com sua capacidade de processar e dar sentido a esses dados em escala. Eles podem lidar com tarefas como análise de sentimento, classificação de texto, extração de informações e muito mais, fornecendo informações valiosas.
Seja identificando tendências de postagens de mídia social ou avaliando o sentimento do cliente a partir de avaliações, os LLMs estão ajudando as empresas a navegar na grande quantidade de dados não estruturados e a tomar decisões baseadas em dados.
O mercado de PNL em expansão
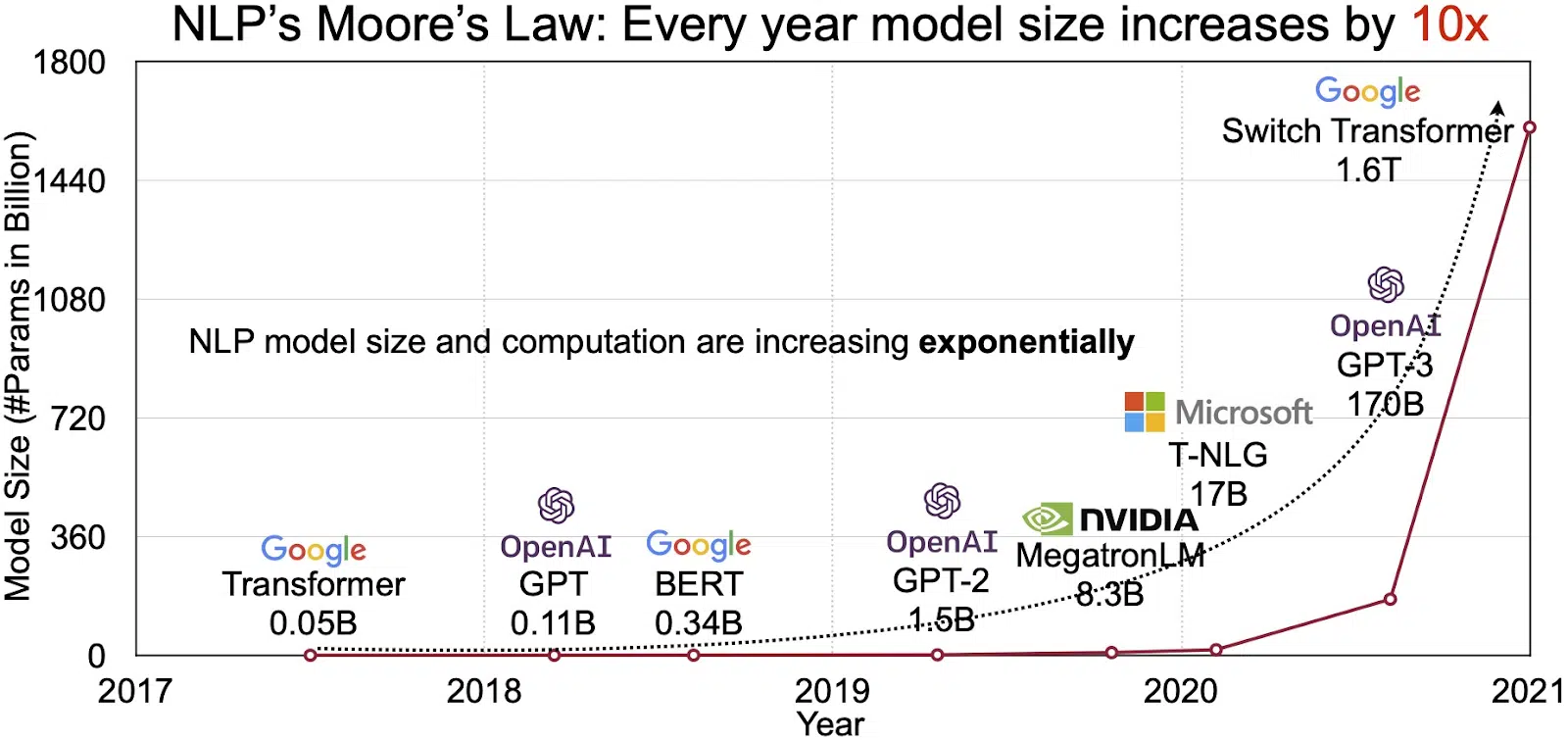
O potencial dos LLMs se reflete no mercado de rápido crescimento para processamento de linguagem natural (NLP). Analistas projetam expansão do mercado de NLP de US$ 11 bilhões em 2020 para mais de US$ 35 bilhões em 2026. Mas não é apenas o tamanho do mercado que está se expandindo. Os próprios modelos também estão crescendo, tanto em tamanho físico quanto no número de parâmetros que manipulam. A evolução dos LLMs ao longo dos anos, como pode ser visto na figura abaixo (fonte da imagem: link), ressalta sua crescente complexidade e capacidade.
Casos de uso populares de grandes modelos de linguagem
Aqui estão alguns dos principais e mais comuns casos de uso do LLM:
- Gerando texto em linguagem natural: Os Large Language Models (LLMs) combinam o poder da inteligência artificial e da linguística computacional para produzir autonomamente textos em linguagem natural. Eles podem atender a diversas necessidades do usuário, como escrever artigos, criar músicas ou se envolver em conversas com os usuários.
- Tradução através de máquinas: Os LLMs podem ser efetivamente empregados para traduzir texto entre qualquer par de idiomas. Esses modelos exploram algoritmos de aprendizado profundo, como redes neurais recorrentes, para compreender a estrutura linguística dos idiomas de origem e de destino, facilitando assim a tradução do texto de origem para o idioma desejado.
- Criação de conteúdo original: Os LLMs abriram caminhos para as máquinas gerarem conteúdo coeso e lógico. Esse conteúdo pode ser usado para criar postagens de blog, artigos e outros tipos de conteúdo. Os modelos exploram sua profunda experiência de aprendizado profundo para formatar e estruturar o conteúdo de uma maneira nova e amigável.
- Análise de Sentimentos: Uma aplicação intrigante dos Large Language Models é a análise de sentimento. Nele, o modelo é treinado para reconhecer e categorizar estados emocionais e sentimentos presentes no texto anotado. O software pode identificar emoções como positividade, negatividade, neutralidade e outros sentimentos complexos. Isso pode fornecer informações valiosas sobre o feedback do cliente e opiniões sobre vários produtos e serviços.
- Compreendendo, Resumindo e Classificando o Texto: Os LLMs estabelecem uma estrutura viável para o software de IA interpretar o texto e seu contexto. Ao instruir o modelo a entender e examinar grandes quantidades de dados, os LLMs permitem que os modelos de IA compreendam, resumam e até mesmo categorizem o texto em diversas formas e padrões.
- Respondendo a perguntas: Os Large Language Models equipam os sistemas de resposta a perguntas (QA) com a capacidade de perceber e responder com precisão à consulta de linguagem natural de um usuário. Exemplos populares desse caso de uso incluem ChatGPT e BERT, que examinam o contexto de uma consulta e analisam uma vasta coleção de textos para fornecer respostas relevantes às perguntas do usuário.

Marcação de parte do discurso (POS)
As palavras nas frases são marcadas com sua função gramatical, como verbos, substantivos, adjetivos etc. Esse processo ajuda o modelo a compreender a gramática e as ligações entre as palavras.

Reconhecimento de entidade nomeada (NER)
Entidades nomeadas como organizações, locais e pessoas dentro de uma frase são marcadas. Este exercício ajuda o modelo a interpretar os significados semânticos de palavras e frases e fornece respostas mais precisas.

Análise de Sentimentos
Os dados de texto recebem rótulos de sentimento como positivo, neutro ou negativo, ajudando o modelo a compreender o tom emocional das frases. É particularmente útil para responder a perguntas envolvendo emoções e opiniões.
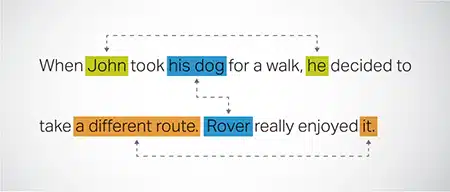
Resolução de Correferência
Identificar e resolver casos em que a mesma entidade é referida em diferentes partes de um texto. Essa etapa ajuda o modelo a entender o contexto da frase, levando a respostas coerentes.
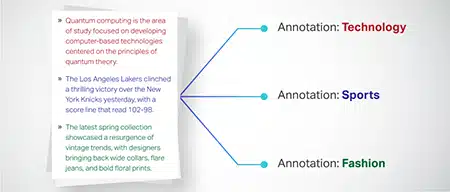
Classificação de Texto
Os dados de texto são categorizados em grupos predefinidos, como análises de produtos ou artigos de notícias. Isso auxilia o modelo a discernir o gênero ou tema do texto, gerando respostas mais pertinentes.
Oferta de Shaip
Saip oferece uma ampla gama de serviços para ajudar as organizações a gerenciar, analisar e aproveitar ao máximo seus dados.
Raspagem de Dados na Web
Um serviço importante oferecido pela Shaip é a raspagem de dados. Isso envolve a extração de dados de URLs específicos do domínio. Ao utilizar ferramentas e técnicas automatizadas, a Shaip pode extrair de forma rápida e eficiente grandes volumes de dados de vários sites, manuais de produtos, documentação técnica, fóruns on-line, análises on-line, dados de atendimento ao cliente, documentos regulamentares do setor, etc. coleta de dados relevantes e específicos de uma infinidade de fontes.

Maquina de tradução
Desenvolva modelos usando extensos conjuntos de dados multilíngues emparelhados com transcrições correspondentes para traduzir texto em vários idiomas. Este processo ajuda a desmantelar os obstáculos linguísticos e promove a acessibilidade da informação.
Extração e Criação de Taxonomia
Shaip pode ajudar na extração e criação de taxonomia. Isso envolve a classificação e categorização de dados em um formato estruturado que reflete as relações entre diferentes pontos de dados. Isso pode ser particularmente útil para empresas na organização de seus dados, tornando-os mais acessíveis e fáceis de analisar. Por exemplo, em uma empresa de comércio eletrônico, os dados do produto podem ser categorizados com base no tipo de produto, marca, preço etc., facilitando a navegação dos clientes no catálogo de produtos.
Recolha de Dados
Nossos serviços de coleta de dados fornecem dados sintéticos ou do mundo real necessários para treinar algoritmos de IA generativos e melhorar a precisão e eficácia de seus modelos. Os dados são imparciais, obtidos de forma ética e responsável, mantendo em mente a privacidade e a segurança dos dados.

Perguntas e Respostas
A resposta a perguntas (QA) é um subcampo do processamento de linguagem natural focado em responder automaticamente a perguntas em linguagem humana. Os sistemas de controle de qualidade são treinados em texto e código extensos, permitindo-lhes lidar com vários tipos de questões, incluindo questões factuais, de definição e baseadas em opinião. O conhecimento do domínio é crucial para o desenvolvimento de modelos de controle de qualidade adaptados a campos específicos, como suporte ao cliente, assistência médica ou cadeia de suprimentos. No entanto, as abordagens generativas de QA permitem que os modelos gerem texto sem conhecimento de domínio, contando apenas com o contexto.
Nossa equipe de especialistas pode estudar minuciosamente documentos ou manuais abrangentes para gerar pares Pergunta-Resposta, facilitando a criação de IA Gerativa para empresas. Essa abordagem pode lidar efetivamente com as consultas do usuário, extraindo informações pertinentes de um corpus extenso. Nossos especialistas certificados garantem a produção de pares de perguntas e respostas de alta qualidade que abrangem diversos tópicos e domínios.

Resumo de Texto
Nossos especialistas são capazes de destilar conversas abrangentes ou diálogos longos, fornecendo resumos sucintos e perspicazes de extensos dados de texto.

Geração de Texto
Treine modelos usando um amplo conjunto de dados de texto em diversos estilos, como artigos de notícias, ficção e poesia. Esses modelos podem gerar vários tipos de conteúdo, incluindo notícias, entradas de blog ou postagens de mídia social, oferecendo uma solução econômica e que economiza tempo para a criação de conteúdo.
Reconhecimento de Voz
Desenvolver modelos capazes de compreender a linguagem falada para diversas aplicações. Isso inclui assistentes ativados por voz, software de ditado e ferramentas de tradução em tempo real. O processo envolve a utilização de um conjunto de dados abrangente composto por gravações de áudio da linguagem falada, emparelhadas com suas transcrições correspondentes.

Recomendações de produtos
Desenvolva modelos usando extensos conjuntos de dados de históricos de compras de clientes, incluindo rótulos que indicam os produtos que os clientes estão inclinados a comprar. O objetivo é fornecer sugestões precisas aos clientes, aumentando assim as vendas e aumentando a satisfação do cliente.
Legenda de imagem
Revolucione seu processo de interpretação de imagens com nosso serviço de legendas de imagens de última geração, orientado por IA. Infundimos vitalidade em imagens, produzindo descrições precisas e contextualmente significativas. Isso abre caminho para possibilidades inovadoras de engajamento e interação com seu conteúdo visual para seu público.

Serviços de conversão de texto em fala de treinamento
Fornecemos um extenso conjunto de dados composto por gravações de áudio de fala humana, ideal para treinar modelos de IA. Esses modelos são capazes de gerar vozes naturais e envolventes para seus aplicativos, proporcionando assim uma experiência sonora diferenciada e imersiva para seus usuários.



