
A chave para superar os obstáculos ao desenvolvimento de IA: dados mais confiáveis
Hoje, a pessoa média agora tem milhões de vezes mais poder de computação no bolso do que a NASA teve para fazer o pouso na lua em 1969. Esse mesmo dispositivo onipresente que demonstra convenientemente uma abundância de poder de computação também está cumprindo outro pré-requisito para a era de ouro da IA: uma abundância de dados. De acordo com informações do Information Overload Research Group, 90% dos dados mundiais foram criados nos últimos dois anos. Agora que o crescimento exponencial do poder de computação finalmente convergiu com um crescimento igualmente meteórico na geração de dados, as inovações em dados de IA estão explodindo tanto que alguns especialistas acreditam que dará início a uma Quarta Revolução Industrial.
Dados da National Venture Capital Association indicam que o setor de IA registrou um investimento recorde de US$ 6.9 bilhões no primeiro trimestre de 2020. Não é difícil ver o potencial das ferramentas de IA porque ele já está sendo explorado ao nosso redor. Alguns dos casos de uso mais visíveis para produtos de IA são os mecanismos de recomendação por trás de nossos aplicativos favoritos, como Spotify e Netflix. Embora seja divertido descobrir um novo artista para ouvir ou um novo programa de TV para assistir compulsivamente, essas implementações são de baixo risco. Outros algoritmos avaliam as pontuações dos testes – determinando parcialmente onde os alunos são aceitos na faculdade – e outros ainda vasculham os currículos dos candidatos, decidindo quais candidatos conseguem um emprego específico. Algumas ferramentas de IA podem até ter implicações de vida ou morte, como o modelo de IA que detecta câncer de mama (que supera os médicos).
Apesar do crescimento constante nos exemplos do mundo real de desenvolvimento de IA e do número de startups que competem para criar a próxima geração de ferramentas transformacionais, os desafios para o desenvolvimento e implementação eficazes permanecem. Em particular, a saída de IA é tão precisa quanto a entrada permite, o que significa que a qualidade é primordial.

Navegando por Demandas Complexas de Conformidade
Como se encontrar dados de qualidade não fosse difícil o suficiente, alguns dos setores que mais podem ganhar com as inovações de dados de IA também são os mais fortemente regulamentados. A saúde talvez seja o melhor exemplo e, embora uma pesquisa da HIT Infrastructure tenha descoberto que 91% dos especialistas do setor acham que a tecnologia pode melhorar o acesso aos cuidados, esse otimismo é atenuado pelo fato de 75% vê-la como uma ameaça à segurança e privacidade do paciente — e os pacientes não são os únicos em risco.
Os regulamentos abrangentes promulgados por meio da Lei de Portabilidade e Responsabilidade de Seguros de Saúde agora estão se cruzando com vários obstáculos locais de conformidade de dados, como o Regulamento Geral de Proteção de Dados da Europa, a Lei de Privacidade do Consumidor da Califórnia nos Estados Unidos e a Lei de Proteção de Dados Pessoais em Cingapura. Essas regulamentações locais serão acompanhadas por muitas outras e, à medida que a telessaúde surge como uma fonte mais significativa de dados de saúde, é provável que as regulamentações ganhem um controle ainda mais rígido dos dados do paciente em trânsito. Como resultado, a plataforma de nuvem segura e compatível da Shaip provará ser um meio ainda mais valioso de acumular e acessar dados de saúde para treinar produtos de IA.
As informações de identificação pessoal podem ser uma ameaça significativa para o desenvolvimento de IA, mas mesmo uma implementação totalmente compatível corre o risco de não fornecer o tipo de resultados precisos que só vêm com dados de treinamento diversos. Um estudo de 2020 no Journal of the American Medical Association demonstrou que os algoritmos de aprendizado de máquina na área médica são mais frequentemente treinados com dados de pacientes na Califórnia, Nova York e Massachusetts. Dado que esses pacientes representam menos de um quinto da população dos EUA, para não falar do resto do mundo, é difícil imaginar como esses modelos poderiam produzir algo além de resultados tendenciosos.

 Reconhecendo a dificuldade em garantir informações compatíveis e geograficamente diversas, a Shaip oferece dados de saúde licenciados de uma ampla variedade de regiões com curadoria específica com o objetivo de construir algoritmos precisos. Esses dados vêm na forma de texto, como registros médicos ou informações de sinistros, imagens de diagnóstico médico, como tomografias computadorizadas, áudio, como notas faladas de médicos ou conversas entre médicos e pacientes, e até mesmo vídeos de resultados de ressonância magnética. Também é completamente desidentificado e anonimizado, protegendo sua organização das implicações éticas e financeiras que podem seguir uma violação de qualquer um dos crescentes regulamentos que regem os dados de origem nacional e internacional.
Reconhecendo a dificuldade em garantir informações compatíveis e geograficamente diversas, a Shaip oferece dados de saúde licenciados de uma ampla variedade de regiões com curadoria específica com o objetivo de construir algoritmos precisos. Esses dados vêm na forma de texto, como registros médicos ou informações de sinistros, imagens de diagnóstico médico, como tomografias computadorizadas, áudio, como notas faladas de médicos ou conversas entre médicos e pacientes, e até mesmo vídeos de resultados de ressonância magnética. Também é completamente desidentificado e anonimizado, protegendo sua organização das implicações éticas e financeiras que podem seguir uma violação de qualquer um dos crescentes regulamentos que regem os dados de origem nacional e internacional.
Superando os obstáculos ao desenvolvimento da IA
Os esforços de desenvolvimento de IA incluem obstáculos significativos, independentemente do setor em que atuam, e o processo de passar de uma ideia viável a um produto de sucesso é repleto de dificuldades. Entre os desafios de adquirir os dados certos e a necessidade de anonimizá-los para cumprir todas as regulamentações relevantes, pode parecer que construir e treinar um algoritmo é a parte mais fácil.
Para dar à sua organização todas as vantagens necessárias no esforço de projetar um novo desenvolvimento inovador de IA, você deve considerar uma parceria com uma empresa como a Shaip. Chetan Parikh e Vatsal Ghiya fundaram a Shaip para ajudar as empresas a projetar os tipos de soluções que podem transformar a saúde nos EUA clientes a transformar ideias atraentes em soluções de IA.
Com nosso pessoal, processos e plataforma trabalhando para sua organização, você pode desbloquear imediatamente os quatro benefícios a seguir e impulsionar seu projeto para um final bem-sucedido:
1. A capacidade de liberar seus cientistas de dados
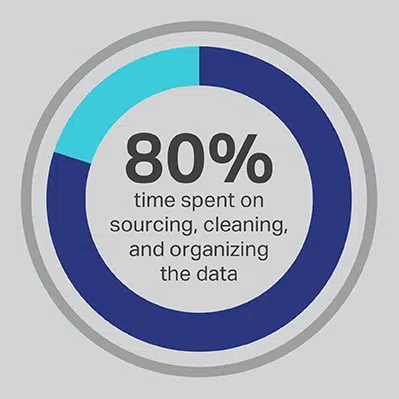
Não há como negar que o processo de desenvolvimento de IA exige um investimento considerável de tempo, mas você sempre pode otimizar as funções que sua equipe gasta mais tempo executando. Você contratou seus cientistas de dados porque eles são especialistas no desenvolvimento de algoritmos avançados e modelos de aprendizado de máquina, mas a pesquisa demonstra consistentemente que esses trabalhadores realmente gastam 80% de seu tempo procurando, limpando e organizando os dados que impulsionarão o projeto. Mais de três quartos (76%) dos cientistas de dados relatam que esses processos mundanos de coleta de dados também são as partes menos favoritas do trabalho, mas a necessidade de dados de qualidade deixa apenas 20% de seu tempo para o desenvolvimento real, o que é o trabalho mais interessante e intelectualmente estimulante para muitos cientistas de dados. Ao obter dados por meio de um fornecedor terceirizado, como a Shaip, uma empresa pode permitir que seus caros e talentosos engenheiros de dados terceirizam seu trabalho como zeladores de dados e, em vez disso, gastem seu tempo nas partes das soluções de IA onde podem produzir mais valor.
2. A capacidade de alcançar melhores resultados
 Muitos líderes de desenvolvimento de IA decidem usar dados de código aberto ou de crowdsourcing para reduzir despesas, mas essa decisão quase sempre acaba custando mais a longo prazo. Esses tipos de dados estão prontamente disponíveis, mas não podem corresponder à qualidade de conjuntos de dados cuidadosamente selecionados. Dados de crowdsourcing em particular estão repletos de erros, omissões e imprecisões e, embora esses problemas às vezes possam ser resolvidos durante o processo de desenvolvimento sob os olhos atentos de seus engenheiros, são necessárias iterações adicionais que não seriam necessárias se você começasse com -dados de qualidade desde o início.
Muitos líderes de desenvolvimento de IA decidem usar dados de código aberto ou de crowdsourcing para reduzir despesas, mas essa decisão quase sempre acaba custando mais a longo prazo. Esses tipos de dados estão prontamente disponíveis, mas não podem corresponder à qualidade de conjuntos de dados cuidadosamente selecionados. Dados de crowdsourcing em particular estão repletos de erros, omissões e imprecisões e, embora esses problemas às vezes possam ser resolvidos durante o processo de desenvolvimento sob os olhos atentos de seus engenheiros, são necessárias iterações adicionais que não seriam necessárias se você começasse com -dados de qualidade desde o início.
Confiar em dados de código aberto é outro atalho comum que vem com seu próprio conjunto de armadilhas. A falta de diferenciação é um dos maiores problemas, porque um algoritmo treinado usando dados de código aberto é mais facilmente replicado do que um construído em conjuntos de dados licenciados. Ao seguir esse caminho, você convida a concorrência de outros participantes no espaço que podem reduzir seus preços e conquistar participação de mercado a qualquer momento. Quando você confia na Shaip, está acessando os dados da mais alta qualidade reunidos por uma força de trabalho habilidosa e gerenciada, e podemos conceder a você uma licença exclusiva para um conjunto de dados personalizado que impede que os concorrentes recriem facilmente sua propriedade intelectual conquistada com muito esforço.
3. Acesso a profissionais experientes
 Mesmo que sua lista interna inclua engenheiros qualificados e cientistas de dados talentosos, suas ferramentas de IA podem se beneficiar da sabedoria que só vem com a experiência. Nossos especialistas no assunto lideraram várias implementações de IA em seus campos e aprenderam lições valiosas ao longo do caminho, e seu único objetivo é ajudá-lo a alcançar o seu.
Mesmo que sua lista interna inclua engenheiros qualificados e cientistas de dados talentosos, suas ferramentas de IA podem se beneficiar da sabedoria que só vem com a experiência. Nossos especialistas no assunto lideraram várias implementações de IA em seus campos e aprenderam lições valiosas ao longo do caminho, e seu único objetivo é ajudá-lo a alcançar o seu.
Com especialistas de domínio identificando, organizando, categorizando e rotulando dados para você, você sabe que as informações usadas para treinar seu algoritmo podem produzir os melhores resultados possíveis. Também realizamos uma garantia de qualidade regular para garantir que os dados atendam aos mais altos padrões e funcionem conforme pretendido não apenas em um laboratório, mas também em uma situação do mundo real.
4. Um cronograma de desenvolvimento acelerado
O desenvolvimento de IA não acontece da noite para o dia, mas pode acontecer mais rápido quando você faz parceria com a Shaip. A coleta e anotação de dados internos cria um gargalo operacional significativo que retém o restante do processo de desenvolvimento. Trabalhar com a Shaip oferece acesso instantâneo à nossa vasta biblioteca de dados prontos para uso, e nossos especialistas poderão fornecer qualquer tipo de entrada adicional que você precisar com nosso profundo conhecimento do setor e rede global. Sem a carga de sourcing e anotação, sua equipe pode começar a trabalhar no desenvolvimento real imediatamente, e nosso modelo de treinamento pode ajudar a identificar imprecisões precoces para reduzir as iterações necessárias para atingir as metas de precisão.
Se você não está pronto para terceirizar todos os aspectos do seu gerenciamento de dados, a Shaip também oferece uma plataforma baseada em nuvem que ajuda as equipes a produzir, alterar e anotar diferentes tipos de dados com mais eficiência, incluindo suporte para imagens, vídeo, texto e áudio . ShaipCloud inclui uma variedade de ferramentas intuitivas de validação e fluxo de trabalho, como uma solução patenteada para rastrear e monitorar cargas de trabalho, uma ferramenta de transcrição para transcrever gravações de áudio complexas e difíceis e um componente de controle de qualidade para garantir qualidade intransigente. O melhor de tudo é que é escalável, para que possa crescer à medida que as várias demandas do seu projeto aumentam.
A era da inovação em IA está apenas começando, e veremos avanços e inovações incríveis nos próximos anos que têm o potencial de remodelar indústrias inteiras ou até mesmo alterar a sociedade como um todo. Na Shaip, queremos usar nossa experiência para servir como uma força transformadora, ajudando as empresas mais revolucionárias do mundo a aproveitar o poder das soluções de IA para atingir metas ambiciosas.
Temos profunda experiência em aplicativos de saúde e IA conversacional, mas também temos as habilidades necessárias para treinar modelos para praticamente qualquer tipo de aplicativo. Para obter mais informações sobre como a Shaip pode ajudar a levar seu projeto da ideia à implementação, dê uma olhada nos muitos recursos disponíveis em nosso site ou entre em contato conosco hoje mesmo.
