
AI, Big Data e Machine Learning continuam a influenciar os formuladores de políticas, empresas, ciência, empresas de mídia e uma variedade de indústrias em todo o mundo. Os relatórios sugerem que a taxa de adoção global da IA está atualmente em 35% em 2022 – um aumento impressionante de 4% em relação a 2021. Outros 42% das empresas estão explorando os muitos benefícios da IA para seus negócios.
Alimentando as muitas iniciativas de IA e Machine Learning soluções são dados. A IA só pode ser tão boa quanto os dados que alimentam o algoritmo. Dados de baixa qualidade podem resultar em resultados de baixa qualidade e previsões imprecisas.
Embora tenha havido muita atenção no desenvolvimento de soluções de ML e IA, falta a consciência do que se qualifica como um conjunto de dados de qualidade. Neste artigo, navegamos na linha do tempo de dados de treinamento de IA de qualidade e identificar o futuro da IA por meio de uma compreensão da coleta de dados e treinamento.
Definição de dados de treinamento de IA
Ao criar uma solução de ML, a quantidade e a qualidade do conjunto de dados de treinamento são importantes. O sistema ML não apenas requer grandes volumes de dados de treinamento dinâmicos, imparciais e valiosos, mas também precisa de muitos deles.
Mas o que são dados de treinamento de IA?
Os dados de treinamento de IA são uma coleção de dados rotulados usados para treinar o algoritmo de ML para fazer previsões precisas. O sistema ML tenta reconhecer e identificar padrões, entender as relações entre os parâmetros, tomar as decisões necessárias e avaliar com base nos dados de treinamento.
Tomemos o exemplo dos carros autônomos, por exemplo. O conjunto de dados de treinamento para um modelo de ML autônomo deve incluir imagens e vídeos rotulados de carros, pedestres, placas de trânsito e outros veículos.
Resumindo, para melhorar a qualidade do algoritmo de ML, você precisa de grandes quantidades de dados de treinamento bem estruturados, anotados e rotulados.
Importância dos dados de treinamento de qualidade e sua evolução
Dados de treinamento de alta qualidade são a entrada principal no desenvolvimento de aplicativos de IA e ML. Os dados são coletados de várias fontes e apresentados de forma desorganizada, inadequada para fins de aprendizado de máquina. Dados de treinamento de qualidade – rotulados, anotados e marcados – estão sempre em um formato organizado – ideal para treinamento de ML.
Dados de treinamento de qualidade tornam mais fácil para o sistema ML reconhecer objetos e classificá-los de acordo com recursos predeterminados. O conjunto de dados pode gerar resultados de modelo ruins se a classificação não for precisa.
Os primeiros dias dos dados de treinamento de IA
Apesar da IA dominar o mundo atual dos negócios e da pesquisa, os primeiros dias antes do ML dominarem Inteligência artificial era bem diferente.
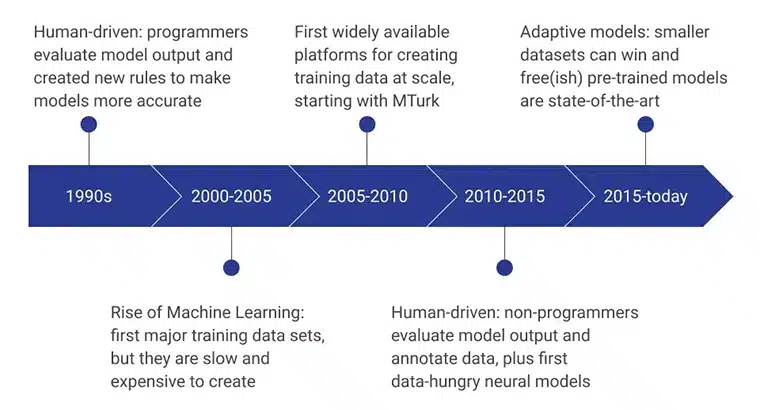
Os estágios iniciais dos dados de treinamento de IA foram alimentados por programadores humanos que avaliaram a saída do modelo, criando consistentemente novas regras que tornaram o modelo mais eficiente. No período de 2000 a 2005, o primeiro grande conjunto de dados foi criado e foi um processo extremamente lento, dependente de recursos e caro. Isso levou ao desenvolvimento de conjuntos de dados de treinamento em escala, e o MTurk da Amazon desempenhou um papel significativo na mudança das percepções das pessoas em relação à coleta de dados. Simultaneamente, a rotulagem e a anotação humanas também decolaram.
Os próximos anos se concentraram em não programadores criando e avaliando os modelos de dados. Atualmente, o foco está em modelos pré-treinados desenvolvidos usando métodos avançados de coleta de dados de treinamento.
Quantidade acima da qualidade
Antigamente, ao avaliar a integridade dos conjuntos de dados de treinamento de IA, os cientistas de dados se concentravam em Quantidade de dados de treinamento de IA acima da qualidade.
Por exemplo, havia um equívoco comum de que grandes bancos de dados fornecem resultados precisos. Acreditava-se que o grande volume de dados era um bom indicador do valor dos dados. A quantidade é apenas um dos principais fatores que determinam o valor do conjunto de dados – o papel da qualidade dos dados foi reconhecido.
A consciência de que qualidade de dados dependia da integridade dos dados, confiabilidade, validade, disponibilidade e pontualidade aumentada. Mais importante ainda, a adequação dos dados para o projeto determinou a qualidade dos dados coletados.
Limitações dos primeiros sistemas de IA devido a dados de treinamento ruins
Dados de treinamento ruins, juntamente com a falta de sistemas de computação avançados, foram uma das razões para várias promessas não cumpridas dos primeiros sistemas de IA.
Devido à falta de dados de treinamento de qualidade, as soluções de ML não conseguiram identificar com precisão os padrões visuais, impedindo o desenvolvimento da pesquisa neural. Embora muitos pesquisadores tenham identificado a promessa de reconhecimento de linguagem falada, a pesquisa ou desenvolvimento de ferramentas de reconhecimento de fala não pôde ser concretizada devido à falta de conjuntos de dados de fala. Outro grande obstáculo ao desenvolvimento de ferramentas de IA de ponta era a falta de recursos computacionais e de armazenamento dos computadores.
A mudança para dados de treinamento de qualidade
Houve uma mudança marcante na consciência de que a qualidade do conjunto de dados é importante. Para que o sistema de ML imite com precisão a inteligência humana e os recursos de tomada de decisão, ele precisa prosperar com dados de treinamento de alto volume e alta qualidade.
Pense em seus dados de ML como uma pesquisa - quanto maior o amostra de dados tamanho, melhor a previsão. Se os dados de amostra não incluírem todas as variáveis, eles podem não reconhecer padrões ou trazer conclusões imprecisas.
Avanços na tecnologia de IA e a necessidade de melhores dados de treinamento
 Os avanços na tecnologia de IA estão aumentando a necessidade de dados de treinamento de qualidade.
Os avanços na tecnologia de IA estão aumentando a necessidade de dados de treinamento de qualidade.O entendimento de que melhores dados de treinamento aumentam a chance de modelos de ML confiáveis deu origem a melhores metodologias de coleta, anotação e rotulagem de dados. A qualidade e a relevância dos dados afetaram diretamente a qualidade do modelo de IA.
 Os avanços na tecnologia de IA estão aumentando a necessidade de dados de treinamento de qualidade.
Os avanços na tecnologia de IA estão aumentando a necessidade de dados de treinamento de qualidade.Maior foco na qualidade e precisão dos dados
Para que o modelo de ML comece a fornecer resultados precisos, ele é alimentado com conjuntos de dados de qualidade que passam por etapas iterativas de refino de dados.
Por exemplo, um ser humano pode ser capaz de reconhecer uma raça específica de cachorro alguns dias após ser apresentado à raça – por meio de fotos, vídeos ou pessoalmente. Os seres humanos extraem de sua experiência e informações relacionadas para lembrar e extrair esse conhecimento quando necessário. No entanto, não funciona tão facilmente para uma Máquina. A máquina deve ser alimentada com imagens claramente anotadas e rotuladas – centenas ou milhares – dessa raça em particular e de outras raças para que ela faça a conexão.
Um modelo de IA prevê o resultado correlacionando as informações treinadas com as informações apresentadas no mundo real. O algoritmo se torna inútil se os dados de treinamento não incluírem informações relevantes.
Importância de dados de treinamento diversos e representativos
O aumento da diversidade de dados também aumenta a competência, reduz o viés e aumenta a representação equitativa de todos os cenários. Se o modelo de IA for treinado usando um conjunto de dados homogêneo, você pode ter certeza de que o novo aplicativo funcionará apenas para uma finalidade específica e atenderá a uma população específica.Um conjunto de dados pode ser enviesado para uma determinada população, raça, gênero, escolha e opiniões intelectuais, o que pode levar a um modelo impreciso.
É importante garantir que todo o fluxo do processo de coleta de dados, incluindo a seleção do conjunto de assuntos, curadoria, anotação e rotulagem, seja adequadamente diverso, equilibrado e representativo da população.
 O aumento da diversidade de dados também aumenta a competência, reduz o viés e aumenta a representação equitativa de todos os cenários. Se o modelo de IA for treinado usando um conjunto de dados homogêneo, você pode ter certeza de que o novo aplicativo funcionará apenas para uma finalidade específica e atenderá a uma população específica.
O aumento da diversidade de dados também aumenta a competência, reduz o viés e aumenta a representação equitativa de todos os cenários. Se o modelo de IA for treinado usando um conjunto de dados homogêneo, você pode ter certeza de que o novo aplicativo funcionará apenas para uma finalidade específica e atenderá a uma população específica.O futuro dos dados de treinamento de IA
O sucesso futuro dos modelos de IA depende da qualidade e quantidade de dados de treinamento usados para treinar os algoritmos de ML. É fundamental reconhecer que essa relação entre qualidade e quantidade de dados é específica da tarefa e não tem uma resposta definitiva.
Em última análise, a adequação de um conjunto de dados de treinamento é definida por sua capacidade de executar de forma confiável para o propósito para o qual foi criado.
Avanços na coleta de dados e técnicas de anotação
Como o ML é sensível aos dados alimentados, é vital otimizar a coleta de dados e as políticas de anotação. Erros na coleta de dados, curadoria, deturpação, medições incompletas, conteúdo impreciso, duplicação de dados e medições errôneas contribuem para a qualidade insuficiente dos dados.
A coleta automatizada de dados por meio de mineração de dados, raspagem da web e extração de dados está abrindo caminho para uma geração de dados mais rápida. Além disso, conjuntos de dados pré-empacotados atuam como uma técnica de coleta de dados de correção rápida.
Crowdsourcing é outro método inovador de coleta de dados. Embora a veracidade dos dados não possa ser garantida, é uma excelente ferramenta para obter imagem pública. Finalmente, especializado coleta de dados os especialistas também fornecem dados obtidos para fins específicos.
Maior ênfase em considerações éticas em dados de treinamento
Com os rápidos avanços na IA, várias questões éticas surgiram, especialmente na coleta de dados de treinamento. Algumas considerações éticas na coleta de dados de treinamento incluem consentimento informado, transparência, viés e privacidade de dados.Como os dados agora incluem tudo, desde imagens faciais, impressões digitais, gravações de voz e outros dados biométricos críticos, está se tornando extremamente importante garantir a adesão a práticas legais e éticas para evitar processos judiciais caros e danos à reputação.
O potencial para dados de treinamento diversificados e de qualidade ainda melhor no futuro
Existe um grande potencial para dados de treinamento diversificados e de alta qualidade no futuro. Graças à consciência da qualidade dos dados e à disponibilidade de provedores de dados que atendem às demandas de qualidade das soluções de IA.
Os provedores de dados atuais são adeptos do uso de tecnologias inovadoras para obter grandes quantidades de diversos conjuntos de dados de forma ética e legal. Eles também têm equipes internas para rotular, anotar e apresentar os dados personalizados para diferentes projetos de ML.
 Com os rápidos avanços na IA, várias questões éticas surgiram, especialmente na coleta de dados de treinamento. Algumas considerações éticas na coleta de dados de treinamento incluem consentimento informado, transparência, viés e privacidade de dados.
Com os rápidos avanços na IA, várias questões éticas surgiram, especialmente na coleta de dados de treinamento. Algumas considerações éticas na coleta de dados de treinamento incluem consentimento informado, transparência, viés e privacidade de dados.Conclusão
É importante fazer parceria com fornecedores confiáveis com um conhecimento profundo de dados e qualidade para desenvolver modelos de IA de ponta. A Shaip é a principal empresa de anotações especializada em fornecer soluções de dados personalizadas que atendem às necessidades e objetivos do seu projeto de IA. Seja nosso parceiro e explore as competências, o compromisso e a colaboração que oferecemos.


