
O reconhecimento automático de fala (ASR) percorreu um longo caminho. Embora tenha sido inventado há muito tempo, quase nunca foi usado por ninguém. No entanto, o tempo e a tecnologia mudaram significativamente. A transcrição de áudio evoluiu substancialmente.
Tecnologias como IA (Inteligência Artificial) impulsionaram o processo de tradução de áudio para texto para resultados rápidos e precisos. Como resultado, seus aplicativos no mundo real também aumentaram, com alguns aplicativos populares como Tik Tok, Spotify e Zoom incorporando o processo em seus aplicativos móveis.
Então, vamos explorar o ASR e descobrir por que ele é uma das tecnologias mais populares em 2022.
O que é fala para texto?
A fala em texto é uma tecnologia aprimorada por IA que traduz a fala humana de um formato analógico para um formato digital. Além disso, a forma digital dos dados coletados é transcrita em um formato de texto.
A fala para texto é muitas vezes confundida com o reconhecimento de voz, que é totalmente diferente desse método. No reconhecimento de voz, o foco está na identificação dos padrões de voz das pessoas, enquanto, neste método, o sistema tenta identificar as palavras que estão sendo faladas.
Nomes comuns de fala para texto
Essa tecnologia avançada de reconhecimento de fala também é popular e conhecida pelos nomes:
- Reconhecimento automático de fala (ASR)
- Reconhecimento de fala
- Reconhecimento de voz do computador
- Transcrição de áudio
- Leitura de tela
Compreendendo o funcionamento do reconhecimento automático de fala
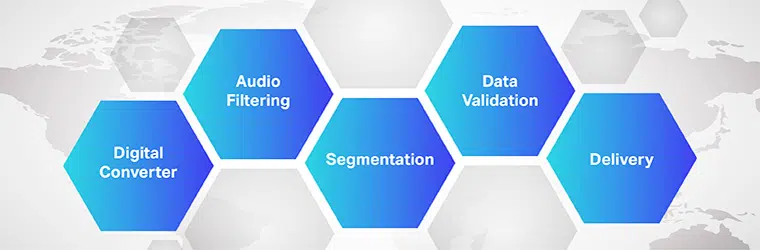
O funcionamento do software de tradução de áudio para texto é complexo e envolve a implementação de várias etapas. Como sabemos, o speech-to-text é um software exclusivo projetado para converter arquivos de áudio em um formato de texto editável; ele faz isso aproveitando o reconhecimento de voz.
Extração
- Inicialmente, usando um conversor analógico-digital, um programa de computador aplica algoritmos linguísticos aos dados fornecidos para distinguir vibrações de sinais auditivos.
- Em seguida, os sons relevantes são filtrados medindo as ondas sonoras.
- Além disso, os sons são distribuídos/segmentados em centésimos ou milésimos de segundos e comparados com fonemas (uma unidade de som mensurável para diferenciar uma palavra de outra).
- Os fonemas são ainda executados através de um modelo matemático para comparar os dados existentes com palavras, frases e frases conhecidas.
- A saída está em um arquivo de texto ou áudio baseado em computador.
[Leia também: Uma Visão Abrangente do Reconhecimento Automático de Fala]

Quais são os usos da fala para texto?
Existem vários usos de software de reconhecimento automático de fala, como
- Pesquisa de conteúdo: A maioria de nós deixou de digitar letras em nossos telefones para pressionar um botão para que o software reconheça nossa voz e forneça os resultados desejados.
- Atendimento ao Cliente: Chatbots e assistentes de IA que podem orientar os clientes nas poucas etapas iniciais do processo se tornaram comuns.
- Legendas em tempo real: Com o aumento do acesso global ao conteúdo, a legendagem em tempo real tornou-se um mercado importante e importante, impulsionando o ASR para seu uso.
- Documentação Eletrônica: Vários departamentos de administração começaram a usar o ASR para cumprir os propósitos de documentação, atendendo a maior velocidade e eficiência.
Quais são os principais desafios para o reconhecimento de fala?
Anotação de áudio ainda não atingiu o ápice de seu desenvolvimento. Ainda há muitos desafios que os engenheiros estão tentando enfrentar para tornar o sistema eficiente, como
- Ganhando controle sobre sotaques e dialetos.
- Compreender o contexto das frases faladas.
- Separação de ruídos de fundo para amplificar a qualidade de entrada.
- Alternando o código para diferentes idiomas para um processamento eficiente.
- Analisar as pistas visuais utilizadas na fala no caso de arquivos de vídeo.
Transcrições de áudio e desenvolvimento de IA de fala para texto
O maior desafio com o software Automatic Speech Recognition é criar sua saída com 100% de precisão. Como os dados brutos são dinâmicos e um único algoritmo não pode ser aplicado, os dados são anotados para treinar a IA para entendê-los no contexto correto.
Para realizar este processo, tarefas específicas devem ser implementadas, tais como:
 Reconhecimento de Entidade Nomeada (NER): NER é o processo de identificar e segmentar diferentes entidades nomeadas em categorias específicas.
Reconhecimento de Entidade Nomeada (NER): NER é o processo de identificar e segmentar diferentes entidades nomeadas em categorias específicas.- Análise de Sentimentos e Tópicos: O software usando vários algoritmos conduz a análise de sentimento dos dados fornecidos para fornecer resultados sem erros.
 Reconhecimento de Entidade Nomeada (NER):
Reconhecimento de Entidade Nomeada (NER): - Análise de intenção e conversa: A detecção de intenção visa treinar a IA para reconhecer a intenção do falante. É usado principalmente para criar chatbots com inteligência artificial.
Conclusão
A tecnologia de fala para texto está em um ótimo estágio no momento. Com mais dispositivos digitais incorporando pesquisa por voz e assistentes de controle em seus aplicativos, a demanda por transcrição de áudio deve aumentar. Se você deseja adicionar esse recurso impressionante ao seu aplicativo, entre em contato com os especialistas em coleta de dados de fala da Shaip para saber todos os detalhes.


